Notre métier vit une période de migration massive de ses infrastructures vers le Cloud. Un monde ou les services doivent être en toutes circonstances disponibles. Les applications doivent être stateless, scalables, légères et rapides à lancer.
Spring Boot est le premier à avoir tiré l’épingle de son jeu, sachez cependant qu’il n’est pas le seul sur le marché, bien au contraire.

Fin 2016 la fondation Eclipse a lancé l’initiative MicroProfile autour de deux idées :
- Définir un sous ensemble de spécifications JakartaEE pour proposer un serveur plus léger
- Définir de nouvelles spécifications pour une meilleure intégration au cloud
Voici le détail de la dernière version :

Vous retrouverez l’ensemble des spécifications sur le compte Github de la Fondation Eclipse. A noter qu’elle dispose de son propre système de validation de spécifications, l’Eclipse Foundation Specification Process (EFSP). Une nouvelle release est publiée tous les trimestres. L’objectif est que ces composants fassent l’objet d’une JCP (Java Community Process) pour intégrer les JSR (Java Specification Requests).
Mais de quoi est composé une spécification Eclipse Microprofile ?
- La spécification sous forme asciidoc
- L’API, ensemble d’interfaces / énumérations Java permettant de définir les fonctionnalités à implémenter
- Suite de tests appelée TCK (Technology Compatibility Kit) permettant de valider une implémentation
N’hésitez pas à y jeter un coup d’œil, les spécifications sont de véritables mines d’or. Elles décrivent et détaillent l’ensemble des fonctionnalités qui la compose. En les consultant vous y découvrirez peut être une feature qui vous sera utile !
N’oublions pas qu’il s’agit de spécifications, vous ne trouverez pas d’implémentation dans ce type de repos.
Faisons un petit tour du propriétaire
J’ai découpé les spécifications en 3 catégories.
1) Les composants JakartaEE
Il s’agit de composants repris des spécifications JakartaEE, ils forment les fondations de notre MicroProfile (n’hésitez pas à lire l’article JakartaEE sur notre blog).
CDI
Context and Dependency Injection est le mécanisme central sur lequel se repose bon nombre de composants. Ce système permet de limiter le couplage entre les objets en facilitant le remplacement des implémentations. La plupart de ses fonctionnalités s’effectuent en phase de compilation.
@Produces
@ApplicationScoped
public static ObjectMapper creerMapper() {
return new ObjectMapper();
}
...
@Inject
FishService fishService;
@Inject
ObjectMapper objectMapper;JAX-RS
Je ne m’attarderai pas sur la spécification standardisant les applications Rest bien connue de tous. Il s’agit certainement avec CDI de la spécification la plus fournie en fonctionnalités.
JSON-P
Spécification permettant de faciliter la manipulation de json (parsing, création, transformation, recherche).
JsonBuilderFactory bf = Json.createBuilderFactory(null)
JsonArray array = bf.createArrayBuilder()
.add(bf.createObjectBuilder()
.add("id", 1)
.add("name", "Cichlidae")
.add("water_type", 0))
.add(bf.createObjectBuilder()
.add("id", 2)
.add("name", "Cyprinidae")
.add("water_type", 0))
.build();JSON-B
Cette spécification permet de définir la façon de mapper un objet java en json et vice versa.
public class Fish {
public long id;
public String name;
public WaterType waterType;
}
Jsonb jsonb = JsonbBuilder.create();
Fish maurice = new Fish();
maurice.id = 1;
maurice.name = "Maurice";
maurice.waterType= WaterType.FRESH;
String mauriceJson = jsonb.toJson(maurice);
System.out.println(mauriceJson); // {"id":1,"name":"Maurice","waterType": 1}
Spécifications utilitaires
Ces spécifications ne sont pas indispensables au bon fonctionnement de votre projet mais elles vous faciliteront la vie.
Open API
Cette spécification standardise la documentation des API, c’est sur ce standard que repose Swagger.
@GET
@Path("/{fishname}")
@Operation(summary = "Get fish by fish name")
@APIResponse(description = "The fish",
content = @Content(mediaType = "application/json",
schema = @Schema(implementation = Fish.class))),
@APIResponse(responseCode = "400", description = "Fish not found")
public Response getFishByName(
@Parameter(description = "The name that needs to be fetched. Use fish1 for testing. ", required = true) @PathParam("fishname") String fishname)GET /openapi/fish/{fishname}:
get:
summary: Get fish by fish name
operationId: getFishByName
parameters:
- name: fishname
in: path
description: 'The name that needs to be fetched. Use fish1 for testing. '
required: true
schema:
type: string
responses:
default:
description: The fish
content:
application/json:
schema:
$ref: '#/components/schemas/Fish'
400:
description: Fish not foundRest Client
Cette spécification particulièrement riche standardise les clients Rest. La fonctionnalité principale de cette API est de pouvoir créer un proxy de service Rest.
@Path("/fishs")
@Produces("application/json")
@Consumes("application/json")
public interface FishServiceClient {
@GET
@Path("family/{fishFamily}")
Response countByFamily(@PathParam("fishFamily") String fishFamily);
@PUT
Response updateFish(@BeanParam PutFish putFish);
}
public class PutFish {
@HeaderParam("Authorization")
private String authorization;
@PathParam("fishId")
private String fishId;
// getters, setters, constructors omitted
}Fault tolerance
Cette spécification permet de rendre votre application plus résiliente en cas de perte de dépendances externes (service, database, etc).
Prenons l’exemple d’une application affichant le détail d’une fiche d’un poisson. Son contenu doit être affiché même sous forme dégradé. Une partie de ces informations provient d’un service externe qui devient brusquement indisponible.
@Retry(maxRetries = 2)
@Fallback(fallbackMethod= "fallbackForFindFamilyName")
public String findFamilyName(String fishName) {
return fishServiceClient.findFamilyName(fishName);
}
private String fallbackForFindFamilyName() {
return "Missing information";
}JWT Propagation
Json Web Token Propagation nous aide à récupérer les informations sur le Principal du contexte. Il suffit juste d’utiliser des annotations via son intégration à CDI (header, claim et signature).
@Inject
private JsonWebToken callerPrincipal;
@Inject
@Claim("raw_token")
private String rawToken;
@Inject
@Claim("groups")
private Set groups;
@Inject
@Claim("exp")
private long expiration;
@Inject
@Claim("sub")
private String subject;Open tracing
Cette spécification permet de standardiser la manière de tracer les appels dans un contexte distribué. Ces flux pourront être exploités par des outils tels que Jaeger ou Zipkin. Cette fonctionnalité ne nécessite pas d’activation particulière si vous disposez d’une application JAX-RS. Dans le cas contraire il est possible d’utiliser l’annotation @Traced.
Spécifications permettant l’intégration à un environnement Cloud
Microprofile Config
C’est l’une des spécifications que je trouve la plus intéressante, elle standardise le chargement de configurations. Elle est capable de récupérer ces informations depuis plusieurs sources, fichiers, paramètres de lancement du serveur, variables d’environnements etc. Il existe des implémentations vers ZooKeeper Consule ou encore Etcd.
Prenons l’exemple d’une variable d’environnement appelée $SHOP_NAME=FishParadise, que vous souhaitez exploiter dans votre application.
@Inject @ConfigProperty(name="SHOP_NAME", defaultValue="FishMarket")
String shopNameA noter que le fichier de configuration par défaut pour un Microprofile Eclipse est le fichier microprofile-config.properties.
Microprofile Health
Cette spécification permet de sonder l’état d’une application. Elle expose plusieurs endpoints permettant de vérifier que votre application est lancée (Liveness), ou prête à fournir son service (Readyness). Il est possible d’ajouter soi-même ses vérifications en les implémentant.
GET /health/live{
"status" : "UP",
"checks" : [ {
"name" : "DataSourceHealthCheck",
"status" : "UP"
} ]
}Microprofile Metric
Spécification permettant de récupérer des statistiques sur l’usage de l’application. Ces métriques sont divisées en 3 catégories Base, Application, Vendor. Elles sont accessibles via l’url /metrics/[Base|Vendor|Application]. Vous y trouverez des informations sur l’usage du CPU, l’état de la jvm ou encore sur votre pool http. Il est également possible d’ajouter vos propres métriques métier.
La spécification fournit de nombreuses annotations @Counted @ConcurrentGauge @Gauge @Metered @Metric @Timed @SimplyTimed. Elles pourront être appliquées selon les cas, à des méthodes, types ou classes.
@Gauge(unit = MetricUnits.NONE, name = "fishQueueSize")
public int getFishQueueSize() {
return fishQueue.size;
}GET /metrics# TYPE base_jvm_uptime_seconds gauge
# HELP base_jvm_uptime_seconds Displays the start time of the Java virtual machine in milliseconds. This attribute displays the approximate time when the Java virtual machine started.
base_jvm_uptime_seconds{environment="dev",instanceId="9afb9093-e0a9-4518-8b66-852f6b9c310a",serviceName="UNKNOWN",serviceVersion="1.0.0"} 315.14300000000003
# TYPE base_classloader_loadedClasses_total_total counter
# HELP base_classloader_loadedClasses_total_total Displays the total number of classes that have been loaded since the Java virtual machine has started execution.
base_classloader_loadedClasses_total_total{environment="dev",instanceId="9afb9093-e0a9-4518-8b66-852f6b9c310a",serviceName="UNKNOWN",serviceVersion="1.0.0"} 12580
# TYPE base_thread_count gauge
# HELP base_thread_count Displays the current number of live threads including both daemon and non-daemon threads
base_thread_count{environment="dev",instanceId="9afb9093-e0a9-4518-8b66-852f6b9c310a",serviceName="UNKNOWN",serviceVersion="1.0.0"} 28
# TYPE base_memory_committedHeap_bytes gauge
# HELP base_memory_committedHeap_bytes Displays the amount of memory in bytes that is committed for the Java virtual machine to use. This amount of memory is guaranteed for the Java virtual machine to use.
base_memory_committedHeap_bytes{environment="dev",instanceId="9afb9093-e0a9-4518-8b66-852f6b9c310a",serviceName="UNKNOWN",serviceVersion="1.0.0"} 3.16669952E8
# TYPE base_gc_total_total counter
# HELP base_gc_total_total Displays the total number of collections that have occurred. This attribute lists -1 if the collection count is undefined for this collector.
base_gc_total_total{environment="dev",instanceId="9afb9093-e0a9-4518-8b66-852f6b9c310a",name="G1-Young-Generation",serviceName="UNKNOWN",serviceVersion="1.0.0"} 6
# TYPE base_gc_total_total counter
# HELP base_gc_total_total Displays the total number of collections that have occurred. This attribute lists -1 if the collection count is undefined for this collector.
base_gc_total_total{environment="dev",instanceId="9afb9093-e0a9-4518-8b66-852f6b9c310a",name="G1-Old-Generation",serviceName="UNKNOWN",serviceVersion="1.0.0"} 0C’est bien beau de voir les spécifications, mais sans implémentations ça ne fonctionne pas !
Il en existe de nombreuses fournies par Oracle, RedHat, IBM etc. Je vous propose de jeter un coup d’œil sur l’implémentation la plus utilisée (licence apache) :
Mais quels serveurs sont compatibles ?
Voici un web starter permettant de créer votre projet MicroProfile Eclipse.

Vous y trouverez des noms bien connus tel que Wildfly et OpenLiberty TomEE et des petits nouveaux comme Payara, KumuluzEE, Helidon et Quarkus.
Un peu de pratique
J’ai choisi pour ce projet d’utiliser KumuluzEE . Il dispose d’une bonne documentation, de nombreuses implémentations et le support est particulièrement réactif.
Structure du projet:
C:\USERS\BMEYNIER\IDEAPROJECTS\MICROPROFILE-ARTICLE
├───.idea
│ └───libraries
└───src
├───assembly
│ └───conf
│ └───local
│ └───META-INF
├───doc
│ └───postman
└───main
├───docker
│ ├───app
│ └───db
│ ├───init
│ └───scripts
├───filters
├───java
│ └───com
│ └───bmeynier
│ └───article
│ └───microprofile
│ ├───domain
│ │ └───enums
│ ├───repository
│ └───rest
│ └───producer
├───k3s
└───resources
├───META-INF
└───WEB-INFConfiguration du pom
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.eclipse.microprofile</groupId>
<artifactId>microprofile</artifactId>
<version>${microprofile.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>Import des specifications Microprofile
A cela il faut ajouter dans le dépendencyManagement le bom contenant toutes les implémentations fournies par KumuluzEE.
<dependency>
<groupId>com.kumuluz.ee</groupId>
<artifactId>kumuluzee-bom</artifactId>
<version>${kumuluzee.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>Il faut ensuite faire ses courses en choisissant les implémentations dont vous avez besoin.
<dependency>
<groupId>com.kumuluz.ee</groupId>
<artifactId>kumuluzee-servlet-jetty</artifactId>
</dependency>
<dependency>
<groupId>com.kumuluz.ee</groupId>
<artifactId>kumuluzee-jpa-hibernate</artifactId>
</dependency>Jetty en guise de server http et Hibernate pour le JPA
Les MicroProfiles sont très flexibles, j’aurai très bien pu choisir d’autres implémentations telles que Undertow et Eclipse-Link.
Microprofile.properties
kumuluzee.datasources[0].jndi-name = jdbc/FishsDS
kumuluzee.datasources[0].connection-url = ${KUMULUZEE_DATASOURCES0_CONNECTIONURL}
kumuluzee.datasources[0].driver-name = ${KUMULUZEE_DATASOURCES0_DRIVER}
kumuluzee.datasources[0].username = ${KUMULUZEE_DATASOURCES0_USERNAME}
kumuluzee.datasources[0].password = ${KUMULUZEE_DATASOURCES0_PASSWORD}
kumuluzee.datasources[0].pool.max-size = 20
kumuluzee.health.checks.data-source-health-check =
kumuluzee.health.checks.data-source-health-check.type = readiness
kumuluzee.health.checks.data-source-health-check.jndi-name = jdbc/FishsDS
kumuluzee.health.checks.disk-space-health-check =
kumuluzee.health.checks.disk-space-health-check.type = liveness
kumuluzee.health.checks.disk-space-health-check.threshold = 10000Taille du jar:
[baptiste@BMEYNIER Microprofile-Article]$ ls -alhs ./target/
total 30M
4,0K drwxr-xr-x. 7 baptiste baptiste 4,0K 30 avril 07:40 .
4,0K drwxr-xr-x. 6 baptiste baptiste 4,0K 30 avril 07:44 ..
30M -rw-r--r--. 1 baptiste baptiste 30M 30 avril 07:40 microprofile-article-1.0.0-SNAPSHOT.jar
16K -rw-r--r--. 1 baptiste baptiste 15K 30 avril 07:40 microprofile-article-1.0.0-SNAPSHOT.jar.originalVous trouverez dans ce jar de 30Mo votre code source ainsi que toutes les dépendances du serveur, il est exécutable tel quel.
Pour avoir une idée claire de ce que vous embarquez je vous conseille vivement de lancer la commande mvn dependency:tree et d’ouvrir le contenu du jar.
Temps de lancement:
[baptiste@BMEYNIER Microprofile-Article]$ $JAVA_11/bin/java -jar ./target/microprofile-article-1.0.0-SNAPSHOT.jar
2020-04-30 07:34:36.628 INFO -- com.kumuluz.ee.configuration.sources.FileConfigurationSource -- Loading configuration from .properties file: META-INF/microprofile-config.properties
2020-04-30 07:34:36.644 INFO -- com.kumuluz.ee.configuration.sources.FileConfigurationSource -- Configuration successfully read.
2020-04-30 07:34:36.645 INFO -- com.kumuluz.ee.EeApplication -- Initialized configuration source: EnvironmentConfigurationSource
2020-04-30 07:34:36.645 INFO -- com.kumuluz.ee.EeApplication -- Initialized configuration source: SystemPropertyConfigurationSource
2020-04-30 07:34:36.646 INFO -- com.kumuluz.ee.EeApplication -- Initialized configuration source: FileConfigurationSource
2020-04-30 07:34:36.647 INFO -- com.kumuluz.ee.EeApplication -- Initializing KumuluzEE
2020-04-30 07:34:36.647 INFO -- com.kumuluz.ee.EeApplication -- Checking for requirements
2020-04-30 07:34:36.648 INFO -- com.kumuluz.ee.EeApplication -- KumuluzEE running inside a JAR runtime.
[...]
2020-04-30 07:34:39.944 INFO -- org.eclipse.jetty.server.AbstractConnector -- Started ServerConnector@45cd8607{HTTP/1.1,[http/1.1]}{0.0.0.0:8080}
2020-04-30 07:34:39.944 INFO -- org.eclipse.jetty.server.Server -- Started @3776ms
2020-04-30 07:34:39.944 INFO -- com.kumuluz.ee.EeApplication -- KumuluzEE started successfullyConsommation mémoire:
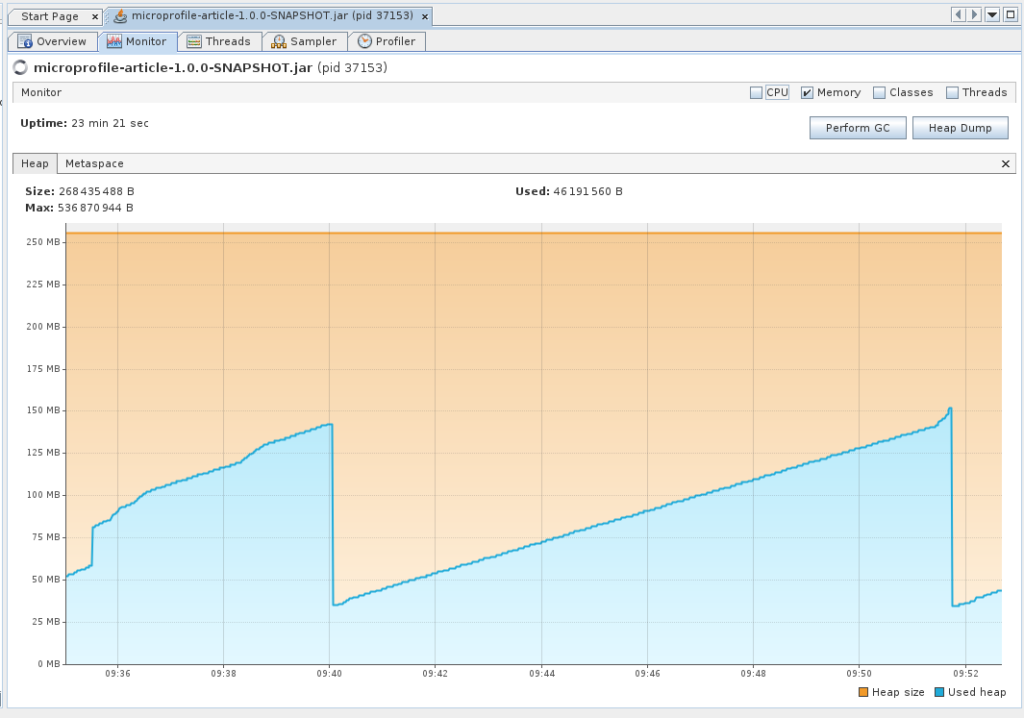
De 35 à 150 Mo (simulation réalisée avec activité modérée) avec comme limite -Xmx256m.
Et si on mettait tout ça dans le Cloud ?
Pour cet exemple j’ai installé une version allégée de Kubernetes sur mon poste, K3s de Rancher.
Nous définirons deux services :
- Une base de données de type H2
- Notre application KumuluzEE
La base de données
apiVersion: apps/v1
kind: Deployment
metadata:
name: fishs-database
namespace: default
spec:
selector:
matchLabels:
app: fishs-database
template:
metadata:
labels:
app: fishs-database
spec:
initContainers:
- name: init-database
image: bmeynier/microprofile/k3s-init-database:v1.0.0
command: ['sh', '-c', '/tmp/createDatabase.sh']
envFrom:
- secretRef:
name: k3s-fishs-secret
volumeMounts:
- name: database
mountPath: /database
containers:
- name: fishs-database
image: bmeynier/microprofile/k3s-database:v1.0.0
volumeMounts:
- name: database
mountPath: /database
ports:
- containerPort: 1521
volumes:
- emptyDir: {}
name: database
---
apiVersion: v1
kind: Service
metadata:
name: fishs-database
namespace: default
spec:
selector:
app: fishs-database
ports:
- port: 1521
targetPort: 1521La base de données est initialisée à l’aide d’un init-container. A noter que le volume est partagé entre l’init-container et le container.
L’application KumuluzEE
apiVersion: apps/v1
kind: Deployment
metadata:
name: fishs-application
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: fishs-application
template:
metadata:
labels:
app: fishs-application
spec:
containers:
- name: fishs-application
image: bmeynier/microprofile/k3s-application:v1.0.0
envFrom:
- configMapRef:
name: k3s-fishs-config
- secretRef:
name: k3s-fishs-secret
# system probes
readinessProbe:
httpGet:
path: /health/ready
port: 8080
initialDelaySeconds: 20
periodSeconds: 10
timeoutSeconds: 3
failureThreshold: 1
livenessProbe:
httpGet:
path: /health/live
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
timeoutSeconds: 3
failureThreshold: 1
resources:
limits:
memory: 256Mi
cpu: 500m
requests:
memory: 64Mi
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: fishs-application
namespace: default
spec:
selector:
app: fishs-application
ports:
- port: 8080
targetPort: 8080
type: LoadBalancerVous remarquerez l’usage de ConfigMap et de Secret. Ces objets Kubernetes seront injectés en tant que variables d’environnement lors du lancement de mon Pod. Je pourrai ensuite les exploiter grâce à MicroProfile Config.
Le second point intéressant concerne la définition des Healths [Live|Ready] qui intéragissent avec MicroProfile Health.
Le composant Microprofile Metric permet de scaler de manière horizontale nos services, nous en parlerons dans un prochain article.
[baptiste@DESKTOP-BMEYNIER Microprofile-Article]$ sudo k3s kubectl get all
[sudo] Mot de passe de baptiste :
NAME READY STATUS RESTARTS AGE
pod/fishs-database-dbc9d98d-984ms 1/1 Running 0 73m
pod/svclb-fishs-application-25tlg 1/1 Running 0 17m
pod/fishs-application-764f69b78d-k7sqx 1/1 Running 0 17m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.43.0.1 <none> 443/TCP 3h41m
service/fishs-database ClusterIP 10.43.188.110 <none> 1521/TCP 73m
service/fishs-application LoadBalancer 10.43.229.234 X.X.X.X 8080:32158/TCP 17m
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/svclb-fishs-application 1 1 1 1 1 <none> 17m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/fishs-database 1/1 1 1 73m
deployment.apps/fishs-application 1/1 1 1 17m
NAME DESIRED CURRENT READY AGE
replicaset.apps/fishs-database-dbc9d98d 1 1 1 73m
replicaset.apps/fishs-application-764f69b78d 1 1 1 17m
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/fishs-application Deployment/fishs-application <unknown>/1k, 0%/50% 1 3 1 16m
Retrouvez le code source sur Gitlab !
Conclusion
- Il existe un large choix de serveurs
- Une nouvelle release sort tous les trimestres
- Ces serveurs sont flexibles, légers et rapides !
- Il est toujours possible de surcharger le comportement d’un composants, il ne s’agit pas d’une boite noire
- Il sont parfaitement intégrés aux environnements cloud