


Introduction
J’ai développé une application me permettant d’historiser les poissons que j’élève dans mes aquariums et ceux de mon association. Il s’agit d’une application Java disposant d’une base de données MySql dont voici le modèle de données.
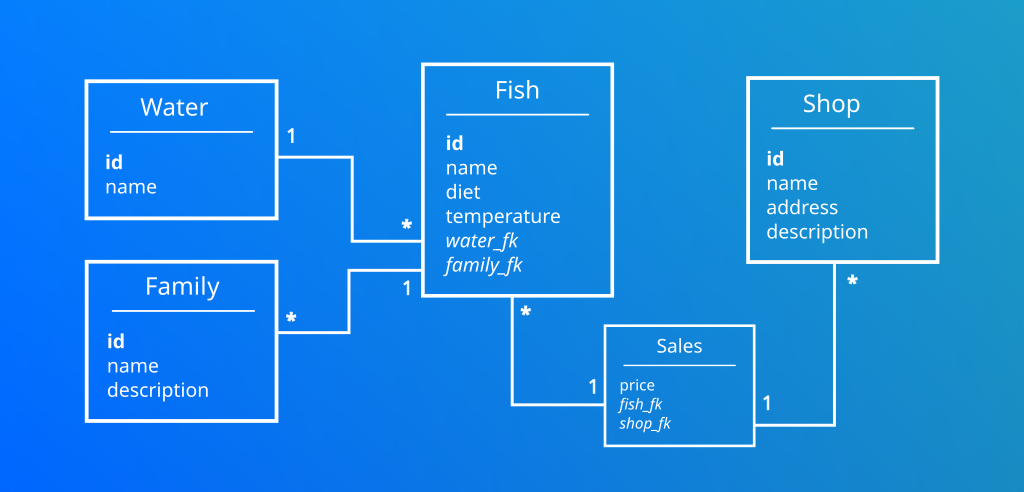
Une société m’a contacté et souhaite créer une application mobile permettant aux professionnels de stocker leurs inventaires de poissons. Une étude a été faite et le grand nombre de données implique l’utilisation d’une base de données que je ne connais pas, Apache Cassandra.
Qu’elles sont les particularités de cette base ?
Théorème de CAP
Monsieur Eric Brewer a créé ce théorème permettant de répartir les bases de données selon leurs caractéristiques.
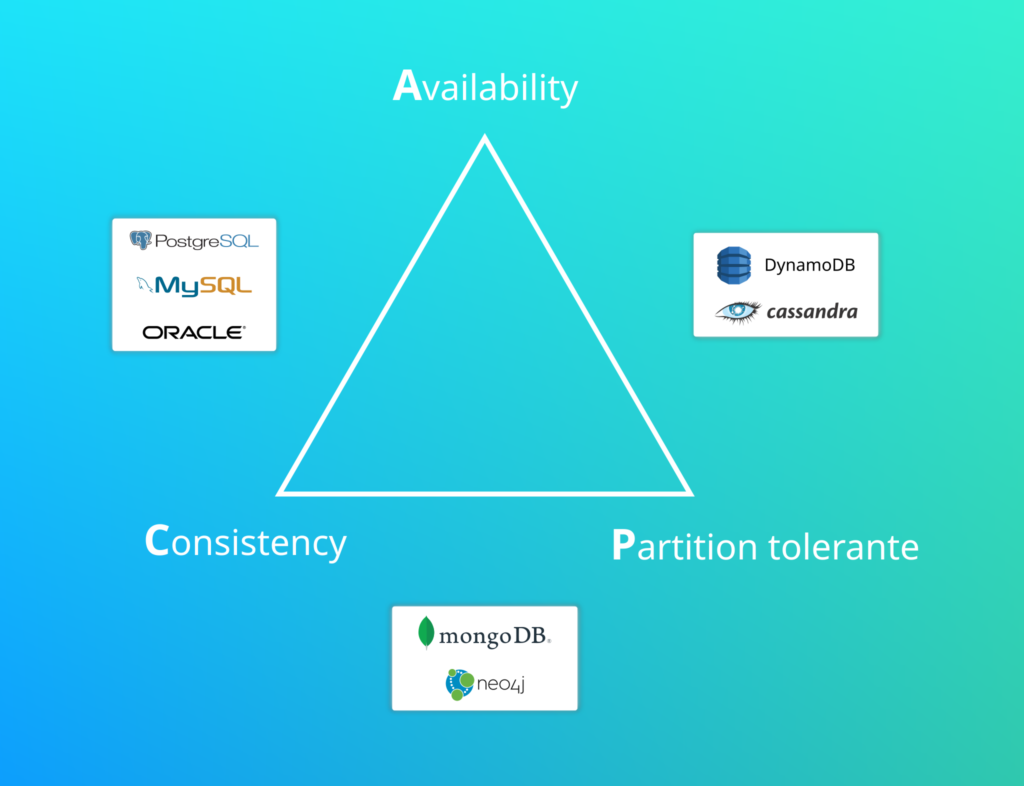
Cohérence (Consistency en anglais) : Tous les nœuds du système voient exactement les mêmes données au même moment .
Disponibilité (Availability en anglais) : garantie que toutes les requêtes reçoivent une réponse ;
Tolérance au partitionnement (Partition Tolerance en anglais) : aucune panne moins importante qu’une coupure totale du réseau ne doit empêcher le système de répondre correctement (ou encore : en cas de morcellement en sous-réseaux, chacun doit pouvoir fonctionner de manière autonome).
Nous savons maintenant que Cassandra est tolérant à la panne et garanti une réponse. Si tout cela est possible, c’est grace à son architecture distribuée.
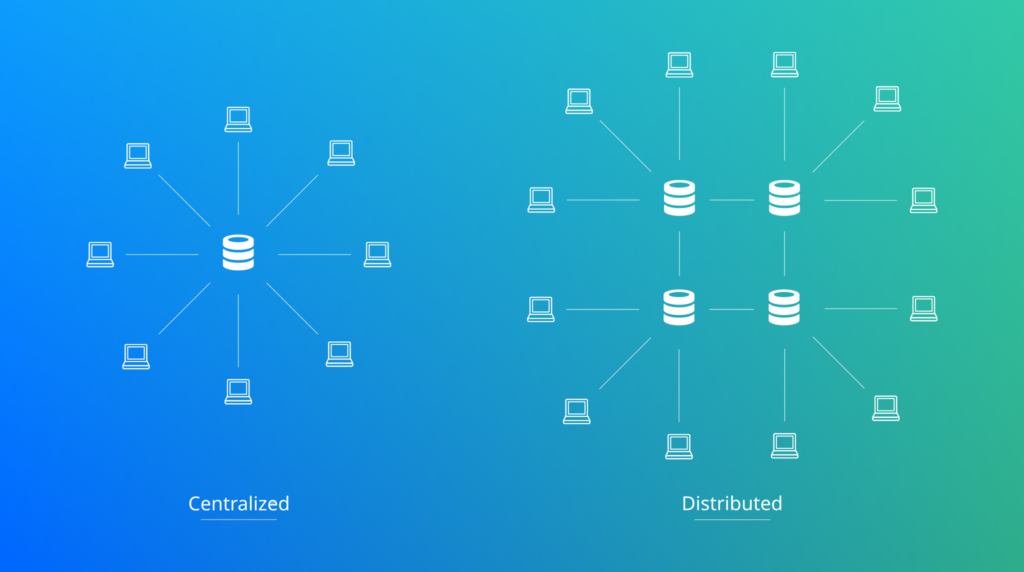
Base de données NoSql
Contrairement aux base de données traditionnelles, Cassandra ne dispose pas de système de jointure. Elles sont couteuses en ressources et ne permettent pas d’accéder à la donnée de manière optimale. L’idée est de créer un modèle de données en une seule table.
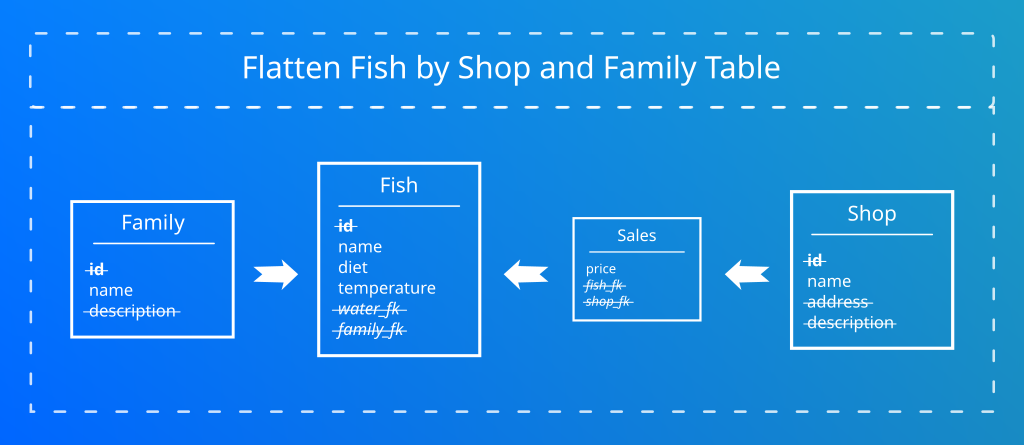
Ici j’ai regroupé l’ensemble de mes tables en une seule. C’est ce que l’on appelle la dénormalisation.
 | A noter que le système de jointure ne pose pas de problème aux architectures non distribués. En revanche elle impliquerait un nombre important de verrous sur un système distribué. |
| Il est évident que tu sais que NoSql signifie “Not Only Sql” et non “Pas SQL” ! |
Le modèle de données sur Cassandra doit être pensé autrement. L’idée est qu’il soit le plus proche possible du besoin client. Dans notre cas il m’est demandé de pouvoir consulter les familles de poisson en fonction des magasins.

C’est ce que l’on appelle le Query First design.
Orienté colonne
Voici de façon schématique de comment sont stockées les données dans une base “classique”.
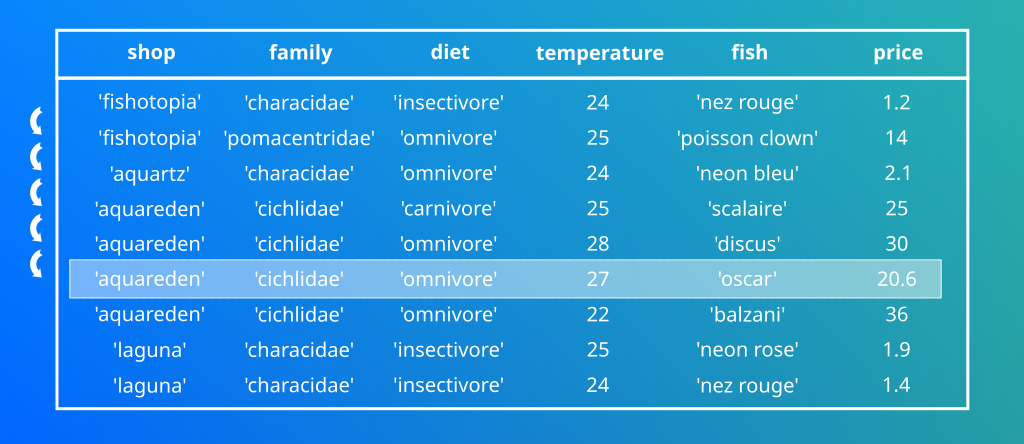
Cassandra est capable de récupèrer les données par colonne!
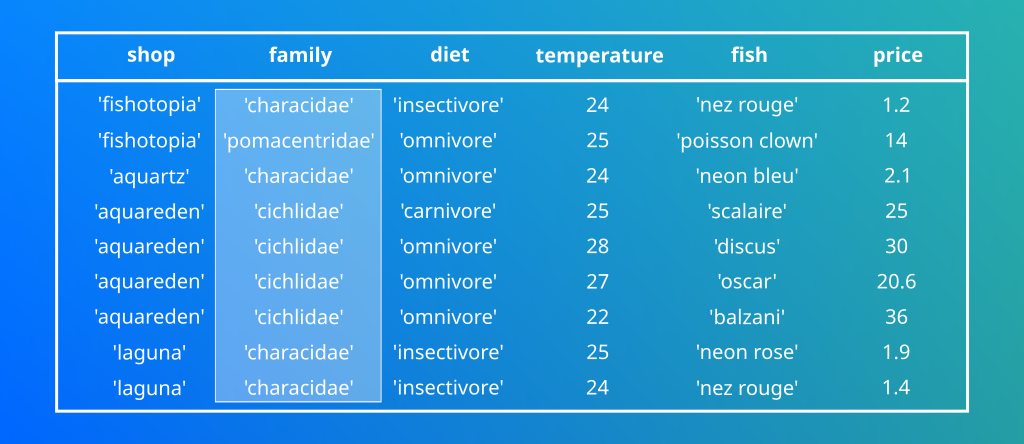
 | Dans Cassandra il est possible de ne pas avoir de valeur pour une colonne. Il ne s’agit pas de valeur null mais bien d’une absence totale de donnée. Imaginez le gain de stockage ! |
Les clefs dans Cassandra:
 | Drôle de nom que le Keyspace… Si je traduis litéralement il s’agit d’un endroit ou il y a des clefs. |
Commençons par créer un Keyspace.
[baptiste@fedora bin]$ ./cqlsh
Connected to Test Cluster at 127.0.0.1:9042
[cqlsh 6.0.0 | Cassandra 4.0.5 | CQL spec 3.4.5 | Native protocol v5]
Use HELP for help.
cqlsh> CREATE KEYSPACE fish_shop WITH replication ={'class':'NetworkTopologyStrategy', 'replication_factor': '3'};
cqlsh> use fish_shop;cqlsh:fish_shop> CREATE TABLE fish_by_shop_and_family
(shop VARCHAR, family VARCHAR, diet VARCHAR, temperature SMALLINT, fish VARCHAR, price FLOAT,
PRIMARY KEY ((shop,family),diet, temperature, fish))
WITH CLUSTERING ORDER BY (diet ASC, temperature DESC);Quelques exemples d’insertions de lignes en base:
INSERT INTO fish_by_shop_and_family (shop, family, diet, temperature, fish, price) VALUES ('aquareden','cichlidae','omnivore',27,'oscar',20.6);
INSERT INTO fish_by_shop_and_family (shop, family, diet, temperature, fish, price) VALUES ('aquareden','cichlidae','omnivore',28,'discus',30);
INSERT INTO fish_by_shop_and_family (shop, family, diet, temperature, fish, price) VALUES ('aquareden','cyprinidae','omnivore',27,'barbus clown',4.6);
INSERT INTO fish_by_shop_and_family (shop, family, diet, temperature, fish, price) VALUES ('laguna','characidae','insectivore',25,'neon rose',1.9);La partition Key
J’ai choisi le couple Shop / Family.
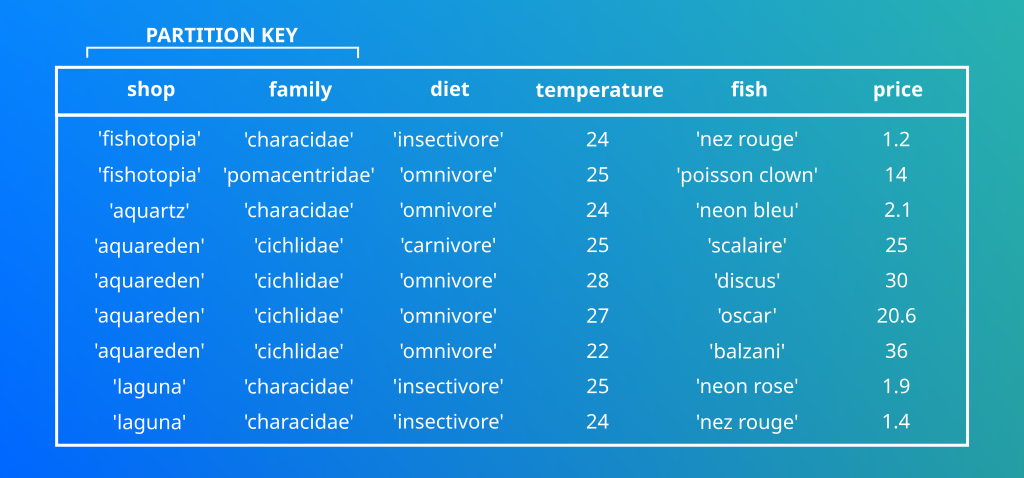
Maintenant que mon Keyspace ma table et mes données sont insérées. Je n’ai qu’une envie, c’est de tester et vérifier que ça fonctionne en faisant une requête CQL.
cqlsh:fish_shop> SELECT * FROM fish_by_shop_and_family WHERE price=30;InvalidRequest: Error from server: code=2200 [Invalid query] message="Cannot execute this query as it might involve data filtering and thus may have unpredictable performance. If you want to execute this query despite the performance unpredictability, use ALLOW FILTERINGMAIS QU’EST CE QUE C’EST QUE CETTE BASE DE DONNEES OU JE NE PEUX PAS REQUETER MES DONNEES !!!
| Bien que cela vous soulagera un temps, jeter son clavier par la fenêtre ne résoudra pas vos problèmes avec Cassandra |
Il y a forcément une raison pour laquelle cette requête ne fonctionne pas, essayons de voir ensemble pourquoi. Revenons sur cette histoire de Keyspace. Je trouve dans la documentation du CQL la fonction Token, que je décide d’appliquer à ma clef.
cqlsh:fish_shop> SELECT token(shop,family),shop,family FROM fish_by_shop_and_family;
system.token(shop, family) | shop | family
----------------------------+------------+---------------
-8244308070285158063 | aquartz | cichlidae
-7298066757405096652 | laguna | cyprinidae
-7298066757405096652 | laguna | cyprinidae
-7192375663116393974 | fishotopia | characidae
-5867784217603879931 | aquareden | pomacentridae
-5867784217603879931 | aquareden | pomacentridaeNous avons vu que Cassandra était une base de données distribuée.
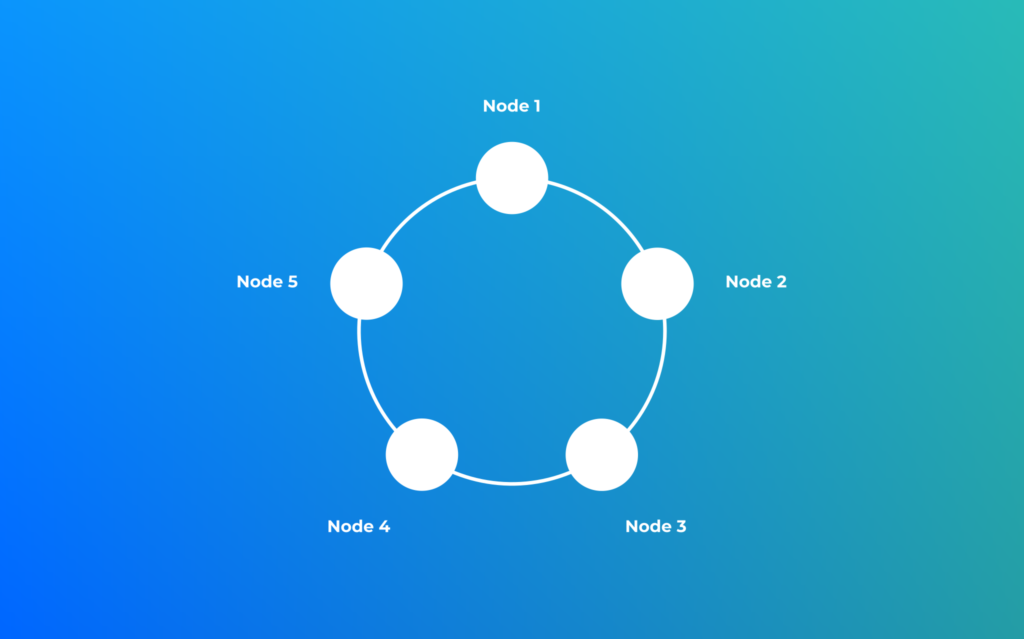
Dans Cassandra la donnée est répartie à travers le cluster, chaque noeud se voit affecter une plage de tokens.
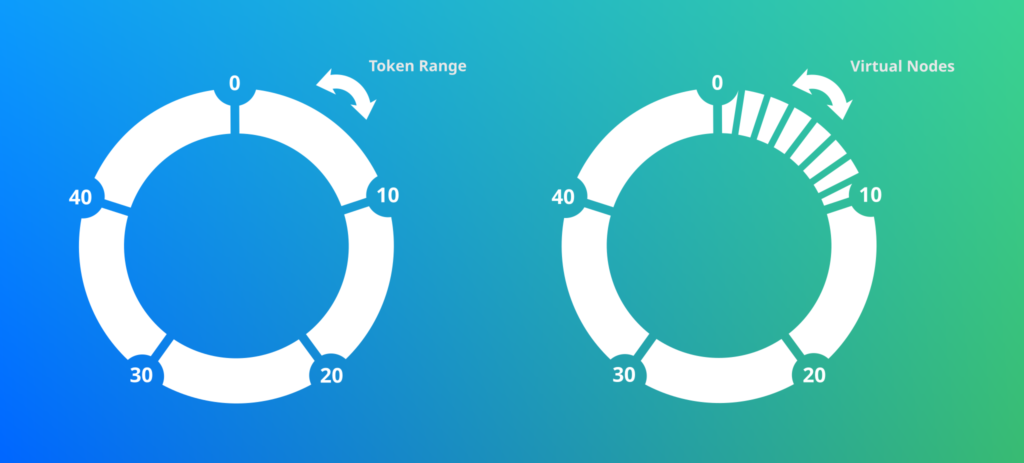
| Cassandra dispose de plusieurs strategies de hashage pour calculer le token. Ce qu’il faut retenir c’est que ces strategies sont idempotantes et que le range de token va de -2^63 à 2^63-1. |
| Les virtual nodes sont des abstractions qui permettent de faire varier le nombre de tokens par node. |
Le nombre de virtual node s’adapte en fonction de la taille du disque dur associé au noeud.
Ici un exemple de comment sont réparties les données à travers le cluster:
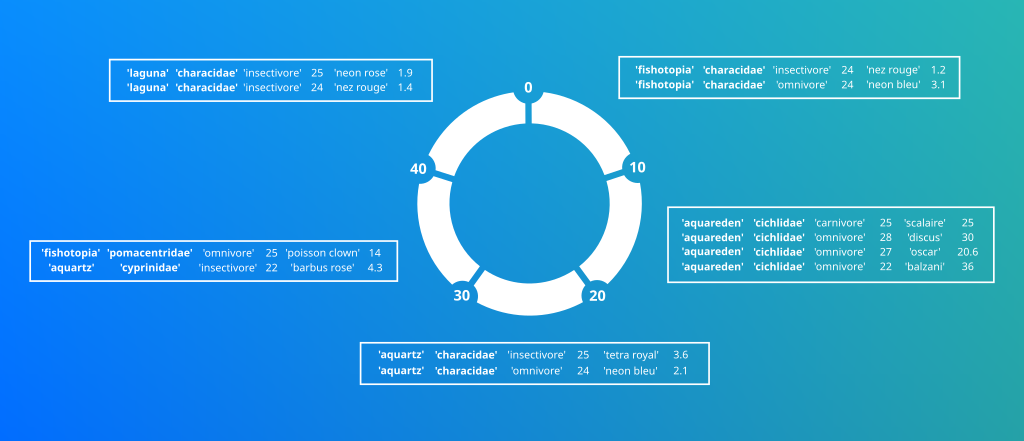
cqlsh:fish_shop> SELECT * FROM fish_by_shop_and_family WHERE shop='aquartz' AND family='characidae'; shop | family | diet | temp | fish | price
---------+------------+-------------+------+--------------+-------
aquartz | characidae | insectivore | 25 | neon rose | 4.1
aquartz | characidae | insectivore | 25 | tetra royal | 3.6
aquartz | characidae | insectivore | 24 | nez rouge | 2.3
aquartz | characidae | omnivore | 25 | tetra citron | 3.4
aquartz | characidae | omnivore | 24 | neon bleu | 2.1 | Il faut faire attention au problème de wide row. Ce problème arrive lorsqu’une clef de partition contient trop de lignes associés (se méfier des partitions key composés d’une seule colonne) |
| La partition key peut etre composée de plusieurs colonnes. Dans ce cas elle s’appelle Composite Partition Key |
| Une petite commande pour trouver ou se situe la donnée: ./nodetool getendpoints fish_shop fish_by_shop_and_family “aquartz:characidae” |
L’algoritme permettant de répartir la donnée à travers le cluster s’appelle un Partitioner. Il s’agit tout simplement d’une fonction qui transforme une Partition Key en Hash. L’algoritme par défaut s’appelle le Murmur3Partitioner.
| Cassandra est un programme OpenSource écrit en Java. N’hésitez pas à cloner la version que vous utilisez. Vous y trouverez les différentes implémentations des fonctionnalités mise à disposition. |
Clustered key
cqlsh:fish_shop> SELECT * FROM fish_by_shop_and_family;Les données semblent étrangement bien ordonnées. Vous remarquerez que les lignes sont automatiquements classées. Je n’ai pourtant rien demandé en SQL standard j’aurai utilisé avec l’instruction ORDER BY dans ma requête. Ici les données sont classées, clusteresées dès leurs insertions grâce au clustered key!
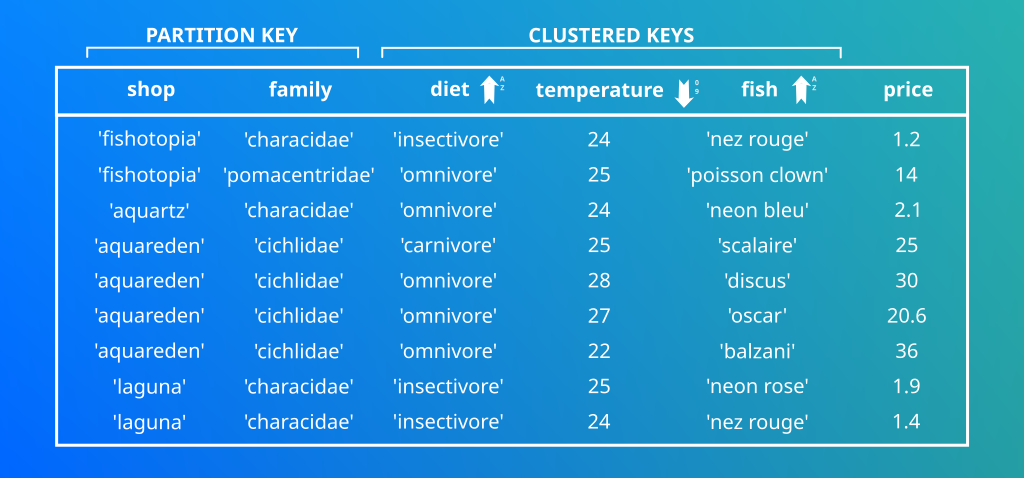
Reprenons une partie de la commande de création de la table:
PRIMARY KEY ((shop,family),diet, temperature, fish))Il s’agit des colonnes qui se situent à droite de la Partition key. Ce sont elles qui définissent l’ordre dans lesquels les données sont restituées. D’ou l’importance de bien réfléchir à sont modèle de données!
| Par défaut si rien n’est précisé la clustered key va classer de manière ASC. Il est possible de demander un classement DESC. Exemple: WITH CLUSTERING ORDER BY (diet ASC, temperature DESC); |
| Les clustered keys sont facultatives, dans ce cas il s’agit d’une clef primaire simple. Dans le cas contraire la clef primaire est dite composée. |
Cette fois si je souhaite connaitre les poissons dont la température d’eau moyenne est 25 degrés.
cqlsh:fish_shop> SELECT * FROM fish_by_shop_and_family WHERE shop='aquartz' AND family='characidae' AND temperature=25;InvalidRequest: Error from server: code=2200 [Invalid query] message="PRIMARY KEY column "temperature" cannot be restricted as preceding column "diet" is not restricted" | Et oui, l’ordre de déclaration des Clustered Colonnes est important lors de la création de votre table! Impossible d’appliquer un prédicat sur une clustered colonne situé à droite sans avoir mensionné les colonnes situées avant. |
Les Ranges Queries
On peut penser que toutes ces contraintes rendent Cassandra difficilement utilisable. En réalité c’est tout l’inverse, la Clustered Key est une fonctionnalité très interessante qui facilite le rapatriement de données par paquet.
cqlsh:fish_shop> SELECT * FROM fish_by_shop_and_family WHERE shop='aquartz' AND family='characidae' AND diet='omnivore' AND 24 < temperature; | Il est possible de définir une Partition Key composée d’une seule colonne avec une valeur unique pour chaque ligne, cependant cet usage rend les Clustered inutiles… |
La Primary Key
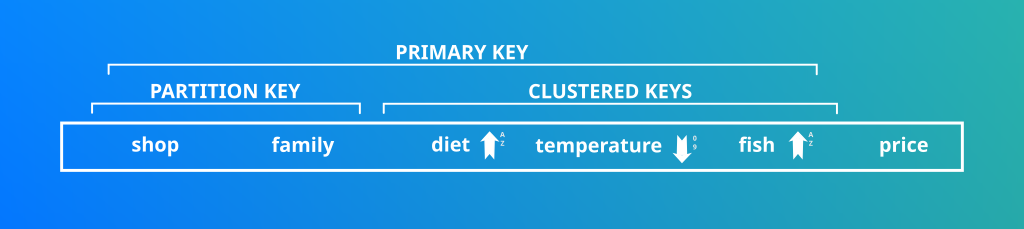
| La clef primaire est unique! Une même combinaison de tous ces champs écraserait les autres champs. A titre d’exemple, le nom du poisson est discriminant et permet de m’assurer de pouvoir insérer n’importe quelle donnée. |
Les clauses Where ne sont applicables que sur les colonnes déclarées comme clef primaire.
Revenons sur l’erreur CQL lorsque l’on interroge un champ n’appartenant pas à la clef primaire:
InvalidRequest: Error from server: code=2200 [Invalid query] message="Cannot execute this query as it might involve data filtering and thus may have unpredictable performance. If you want to execute this query despite the performance unpredictability, use ALLOW FILTERING"A mon sens toute l’architecture de Cassandra est expliquée en un seul message d’erreur!
| L’instruction ALLOW FILTERING ne doit servir qu’en mode débug ! |
Les indexes inversés
Revenons à cette requète qui nous a tant frustré un peu plus haut.
cqlsh:fish_shop> SELECT * FROM fish_by_shop_and_family WHERE price=30;Il existe une technique pour pouvoir interroger ces données. L’idée est de créer une autre table qui stocke pour certaines valeurs de champ la localisation de la donnée dans la table principale.

C’est ce que l’on appelle le predicate push down.
Ecriture de données
La réplication des données
La stratégie de réplication des données est configurée par Keyspace lors de sa création.
Simple Strategy
Il s’agit de la strategie de réplication entre guillemet démo. Elle n’est utile que pour les architectures sur un Datacenter et un Rack (jamais). Elle à le mérite tout de même d’expliquer certains mécanismes de base. Ici nous demandons une réplication des données du Keyspace de trois.
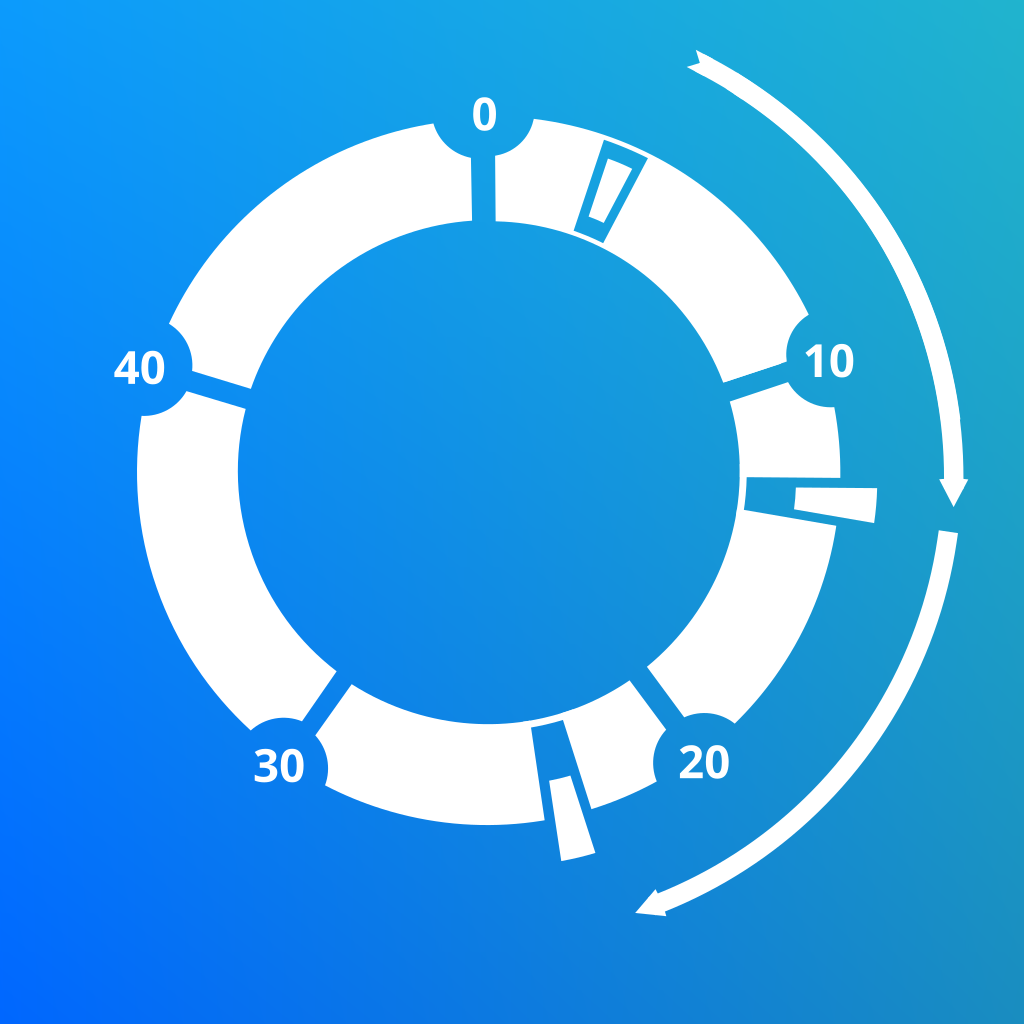
Une fois le token calculé, la réplication suit tout simplement le sens des aiguilles d’une montre.
Ce qu’il faut utiliser en Prod, la Network Topology Strategy
Cette strategie utilise également le sens des aiguilles d’une montre mais tient en plus compte de la topologie Rack/Datacenter.
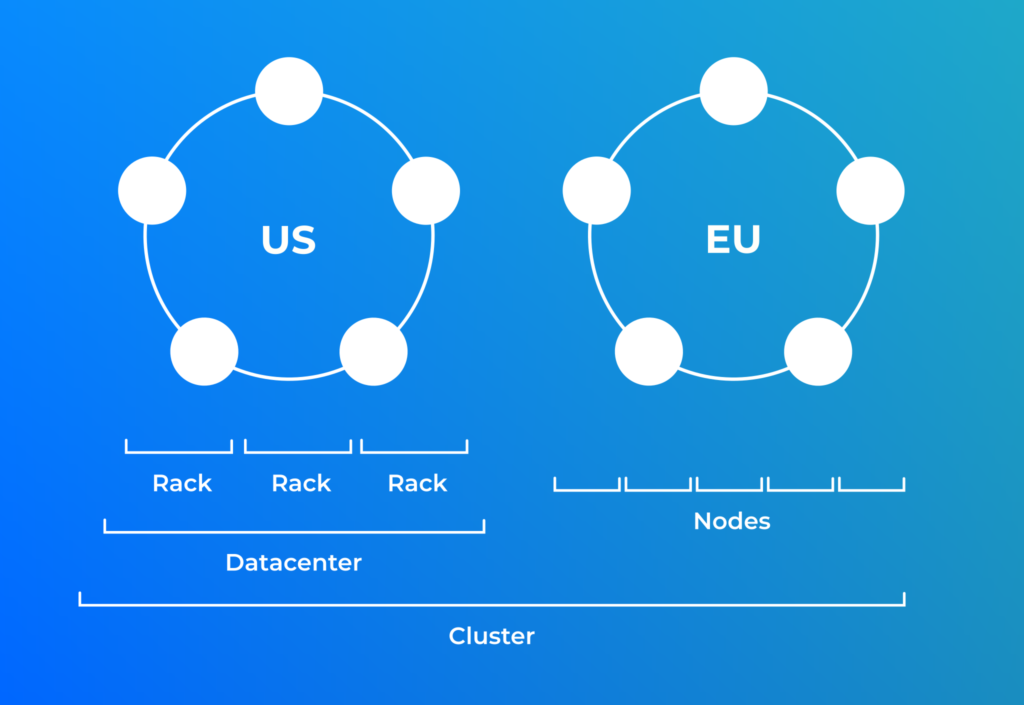
Les données sont réparties sur les différents Racks (groupement physique) au cas ou il y aurait des problèmes d’alimentations éléctrique, matériels ou de réseaux.
Cette strategie implique de renseigner pour chacun des noeuds le couple Datacenter/Rack dans le fichier cassandra-rackdc.properties situé dans le répertoire de conf.
| Cassandra se base sur une architecture Peer to Peer. C’est à dire que chacun des noeuds possède les mêmes fonctionnalités. |
| Il est possible d’avoir une strategie de réplication des données différente en fonction selon le Datacenter |
Gossip Protocol
Cassandra est une entité composée de nombreux individus. La base de données à besoin de maintenir un niveau d’information commun et distribué. Le protocol de dialogue et de transfert des métadonnées s’appelle le Gossip Protocol. Il s’agit d’un protocol assynchrone.



Chaque noeud dispose d’un annuaire avec une date de mise à jour avec les informations suivantes:
- Heartbeat State:
- Date de démarrage du noeud
- Date du dernier Gossip
- Application State:
- Status => Normal Leaving Joining
- Snitch => Localisation
- DC
- Rack
- Schéma
- Keyspaces
- Tables
- Performance
- Load (IO Disk)
- Severity (IO pression tient compte des compactions et des données provenant de /proc/stat iostat utility)
Seed Node
Certains noeuds appelés Seeds ont un rôle un peu spéciaux. Lorsqu’un noeud est arrêté il garde en mémoire sa topology. Lors de son redémarrage ce noeud contactera en premier un Seed node pour s’informer de l’état du cluster. La déclaration de ces noeuds est à faire dans la cassandra.yaml et doit être identique sur l’ensemble du datacenter.
| Il est recommandé d’avoir une petite liste de seed nodes, 3 par datacenter devrait suffir. |
| Les seeds nodes ne sont pas des single points of failure. |
Consistence
Les clients, que se soit en lecture ou écriture, ont la possibilité de choisir leur critère de validité de leur transaction.
Voici la liste des consistences pour l’écriture:
ALL, EACH_QUORUM, QUORUM, LOCAL_QUORUM, ONE, TWO, THREE, LOCAL_ONE, ANYPrenons l’exemple de la consistence TWO dans notre cas ou la donnée est répliquée trois fois:





Vous avez du la voir partout sur internet, la consistence QUORUM. Mais qu’est ce que ca veut dire ?
quorum = (sum_of_replication_factors / 2) + 1Dans notre exemple le Quorum équivaut à une consistence de 2.
| Attention les consistences entre la lecture et l’écriture ne sont pas exactement les même. Vous trouverez le détail ici |




| Il est conseillé d’avoir deux disques séparés. Un pour les commit logs et l’autre pour les SSTables. |
Le flush de la MemTable peut être déclenché de deux façons:
- La taille de la mémoire dépasse un seuil définit dans la configuration (memtable_cleanup_threshold).
- La taille du commit-log approche de sa taille maximale, le flush de la memtable est forcé permettant ainsi libérer des ségments de la commit-log.
| Le Commit log est un fichier ou l’on ne fait qu’ajouter des données (append only). |
| Lors d’une écriture le commit log est priorisé par rapport à la memtable. Cela permet en cas d’arrêt de l’instance de minimiser les pertes. Ce fichier est avant tout utilisé lors du lancement du noeud. |
Il est possible de voir le contenu d’une SSTable en utilisant sstabledump situé dans le répertoire tools
bin]$ ./sstabledump ../../data/data/fish_shop/fish_by_shop_and_family-63d98b205df711eda61a27354021ba50/nb-1-big-Data.db
[
{
"partition" : {
"key" : [ "aquartz", "cichlidae" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 36,
"clustering" : [ "detritivore", 26, "pelmato" ],
"liveness_info" : { "tstamp" : "2022-11-06T17:21:27.002499Z" },
"cells" : [
{ "name" : "price", "value" : 10.3 }
]
}
]
},
{
"partition" : {
"key" : [ "laguna", "cyprinidae" ],
"position" : 73
},
"rows" : [
{
"type" : "row",
"position" : 109,
"clustering" : [ "herbivore", 23, "barbus nigro" ],
"liveness_info" : { "tstamp" : "2022-11-06T17:21:27.311759Z" },
"cells" : [
{ "name" : "price", "value" : 2.4 }
]
},
{
"type" : "row",
"position" : 148,
"clustering" : [ "omnivore", 27, "barbus clown" ],
"liveness_info" : { "tstamp" : "2022-11-06T17:21:27.304076Z" },
"cells" : [
{ "name" : "price", "value" : 3.8 }
]
}
]
},
Nous savons que Cassandra ne garantit pas que la donnée soit identique sur l’ensemble de ses noeuds. Il est pourtant primordiale de connaitre la dernière valeur de la donnée. Pour cela Cassandra stocke lors de chaque insertion sa date de mise à jour. Cette date est utile à bien des mécanismes!
cqlsh:fish_shop> SELECT price, WRITETIME(price) FROM fish_by_shop_and_family;
price | writetime(price)
-------+------------------
10.3 | 1667755287002499
2.4 | 1667755287311759
3.8 | 1667755287304076Lecture
Comment Cassandra lit ses données ?




| Dans mon schéma j’ai représenté la MemTable comme une sorte de Map, en réalité il s’agit d’un arbre binaire équilibré. C’est a dire que la profondeur des branches sont plus ou moins les mêmes à plus ou moins 1 pas. |
Read Repair
Il s’agit d’un mécanisme assynchrone qui permet de re-synchronizer les données lors de la lecture.






| Le Snitch est un algorithme basé sur le Gossip Protocol qui choisira le noeud le plus performant pour transférer la donnée complête. Il existe comme d’habitude plusieurs implémentations notamment le Dynamic Snitch qui tient compte du load et de la severity. |
Suppression des données
S’il n’est pas simple d’écrire une donnée de façon distribuée en tenant compte des pannes, il est encore plus compliqué de gérer les suppressions.
Cassandra est particulièrement performant pour l’écriture et la lecture des données, en revanche il l’est un peu moins pour la suppression.
La suppression se joue en deux étapes:
- Cassandra ne supprime pas la donnée immédiatement. Il va en réalité marquer la donnée avec un objet fort sympathique, un Tombstones. Cette date d’expiration est configurable et est configurable via l’option gc_grace_seconds
- Une fois la date d’expiration atteinte un process appelé Compaction supprime définitivement la donnée.
DELETE FROM fish_by_shop_and_family WHERE shop='aquartz' AND family='cichlidae';Au bout de quelques instants une nouvelle SSTable va être générée uniquement composé du delta.
[
{
"partition" : {
"key" : [ "aquartz", "cichlidae" ],
"position" : 0,
"deletion_info" : {
"marked_deleted" : "2023-01-08T21:26:35.157658Z",
"local_delete_time" : "2023-01-08T21:26:35.15Z"
}
},
"rows" : []
}
] | Certains ORM insèrent des valeurs Null dans des colonnes ce qui déclenche la génération de Tombstones |
Les types de tombstones:
- Cell tombstones
- Row tombstones
- Range tombstones
- Partition tombstones
- TTL tombstones
| Il est préférable d’utiliser les Range tombstones qui occupent moins d’espace disque que la suppression ligne par ligne. |
| Un grand nombre de Tombstones peut entrainer des problèmes de performances! |
Compaction




Dans notre exemple nous n’avons que deux SSTables (aussi appelé segment), dans la réalité il y a souvent bien plus de SSTable. Une execution regroupera deux a deux les segments et les fusionnera.
Fonctionnement sur une machine
[baptiste 4.0.5]$ tree
├── bin
│ ├── cassandra
│ ├── cassandra.in.sh
│ ├── cqlsh
│ ├── cqlsh.py
│ ├── debug-cql
│ ├── nodetool
│ ├── sstableloader
│ ├── sstablescrub
│ ├── sstableupgrade
│ ├── sstableutil
│ ├── sstableverify
│ └── stop-server
├── conf
│ ├── cassandra-env.sh
│ ├── cassandra-jaas.config
│ ├── cassandra-rackdc.properties
│ ├── cassandra-topology.properties
│ ├── cassandra.yaml
│ ├── commitlog_archiving.properties
│ ├── cqlshrc.sample
│ ├── hotspot_compiler
│ ├── jvm11-clients.options
│ ├── jvm11-server.options
│ ├── jvm8-clients.options
│ ├── jvm8-server.options
│ ├── jvm-clients.options
│ ├── jvm-server.options
│ ├── logback-tools.xml
│ ├── logback.xml
│ ├── metrics-reporter-config-sample.yaml
│ ├── README.txt
│ └── triggers
├── data
│ ├── commitlog
│ │ ├── CommitLog-7-1672654779588.log
│ │ └── CommitLog-7-1672654779589.log
│ ├── data
│ │ │ └── fish_by_shop_and_family-245336d082dd11ed9cb22b2b70639517
│ │ ├── system
│ │ ├── system_auth
│ │ │ ├── network_permissions-d46780c22f1c3db9b4c1b8d9fbc0cc23
│ │ │ ├── resource_role_permissons_index-5f2fbdad91f13946bd25d5da3a5c35ec
│ │ │ ├── role_members-0ecdaa87f8fb3e6088d174fb36fe5c0d
│ │ │ ├── role_permissions-3afbe79f219431a7add7f5ab90d8ec9c
│ │ │ └── roles-5bc52802de2535edaeab188eecebb090
│ │ ├── system_distributed
│ │ ├── system_schema
│ │ │ ├── aggregates-924c55872e3a345bb10c12f37c1ba895
│ │ │ ├── columns-24101c25a2ae3af787c1b40ee1aca33f
│ │ │ ├── dropped_columns-5e7583b5f3f43af19a39b7e1d6f5f11f
│ │ │ ├── functions-96489b7980be3e14a70166a0b9159450
│ │ │ ├── indexes-0feb57ac311f382fba6d9024d305702f
│ │ │ ├── keyspaces-abac5682dea631c5b535b3d6cffd0fb6
│ │ │ ├── tables-afddfb9dbc1e30688056eed6c302ba09
│ │ │ ├── triggers-4df70b666b05325195a132b54005fd48
│ │ │ ├── types-5a8b1ca866023f77a0459273d308917a
│ │ │ └── views-9786ac1cdd583201a7cdad556410c985
│ │ └── system_traces
│ │ ├── events-8826e8e9e16a372887533bc1fc713c25
│ │ └── sessions-c5e99f1686773914b17e960613512345
│ ├── hints
│ └── saved_caches
├── doc
├── lib
├── logs
├── pylib
└── tools
├── bin
│ ├── auditlogviewer
│ ├── cassandra.in.sh
│ ├── cassandra-stress
│ ├── cassandra-stressd
│ ├── compaction-stress
│ ├── fqltool
│ ├── generatetokens
│ ├── jmxtool
│ ├── sstabledump
│ ├── sstableexpiredblockers
│ ├── sstablelevelreset
│ ├── sstablemetadata
│ ├── sstableofflinerelevel
│ ├── sstablerepairedset
│ └── sstablesplit
└── libBonus
Qu’est ce qu’un seed node ?
About seed nodes:
- A seed node is used to bootstrap the gossip process for new nodes joining a cluster.
- To learn the topology of the ring, a joining node contacts one of the nodes in the -seeds list in cassandra.yaml.
- The first time you bring up a node in a new cluster, only one node is the seed node.
- The seeds list is a comma delimited list of addresses. Since this example cluster includes 5 nodes, you must change the list from the default value
"127.0.0.1"to the IP address of one of the nodes. - After all nodes are added, all nodes in the datacenter must be configured to use the same seed nodes.
Comment le noeud coordinateur est il désigné ?
The coordinator node is typically chosen by an algorithm which takes “network distance” into account. Any node can act as the coordinator, and at first requests will be sent to the nodes which your driver knows about. But once it connects and understands the topology of your cluster, it may change to a “closer” coordinator.
The coordinator only stores data locally (on a write) if it ends up being one of the nodes responsible for the data’s token range.
Vue matérializée
Quelques commandes
Sources
https://www.simplilearn.com/tutorials/big-data-tutorial/cassandra-architecture
https://fr.wikipedia.org/wiki/Th%C3%A9or%C3%A8me_CAP
https://www.youtube.com/watch?v=jYvKiewV-5Q&list=PL2g2h-wyI4SqIigskyJNAeL2vSTJZU_Qp
https://www.youtube.com/watch?v=oma4xwVbhvk&list=PL2g2h-wyI4SrHMlHBJVe_or_Ryek2THgQ
https://www.youtube.com/watch?v=69pvhO6mK_o&list=PL2g2h-wyI4Spf5rzSmesewHpXYVnyQ2TS
https://www.youtube.com/watch?v=s1xc1HVsRk0&list=PLalrWAGybpB-L1PGA-NfFu2uiWHEsdscD
https://www.scylladb.com/glossary/cassandra-column-family/
https://www.tutorialspoint.com/cassandra/cassandra_data_model.htm
http://www-igm.univ-mlv.fr/~dr/XPOSE2010/Cassandra/modele.html
https://www.fishipedia.fr/fr/poissons/symphysodon-aequifasciatus
https://medium.com/jorgeacetozi/cassandra-architecture-and-write-path-anatomy-51e339bcfe0c
http://abiasforaction.net/apache-cassandra-memtable-flush/
https://www.youtube.com/watch?v=69sHSF0iUqg
https://docs.datastax.com/en/dse/6.8/dse-admin/datastax_enterprise/production/calcTokens.html
https://www.youtube.com/watch?v=lNIrj9VuBQ0
https://anant.us/blog/modern-business/cassandra-sstables-overview/
https://www.scylladb.com/glossary/sstable/
https://medium.com/walmartglobaltech/tombstones-in-apache-cassandra-d0a068a72dcc