


Lors du développement d’une application nous pensons souvent à la maintenabilité du code, sa robustesse et la performance. Il y a un critère que nous mettons souvent de coté c’est la notion de coût de l’infrastructure. Cette problématique se pose de plus en plus, que se soit dans le monde des Cloud publics ou du BigData fort consommateur en ressources. Les frameworks conventionnelles remplissent leurs rôles lorsqu’il s’agit de créer une applications Web, mais ne sont pas réellement conçut pour répondre aux exigences de BigData. Il existe pourtant des paradigmes simples connu depuis des années permettant d’exploiter le hardware de manière efficiente. Vert.x n’est pas un framework mais un ensemble d’outils permettant de répondre efficacement à ces problématiques.
J’ai souvent entendu que pour avoir de meilleurs performances il fallait augmenter la mémoire ou le nombre de threads. Mais est-ce aussi simple que ça ?
Qu’est ce qu’un pools de threads ?
Illustrons notre explication en prenant l’exemple des caisses d’un supermarché
Les clients sont répartis sur l’ensemble des caisses et paient chacun leurs tours.
Ce n’est ni plus ni moins qu’un pool de threads !
En cas de forte affluence il est possible d’ouvrir de nouvelles caisses pour désengorger les files d’attentes.
En informatique chaque pool porte une responsabilité qui lui est propres, entrées/sorties, transactions, accès à la base de données etc etc.
Il existe plusieurs façons de déclarer un pool de thread, notamment en lui définissant une taille minimal et maximal.
ThreadPoolExecutor executorPool = new ThreadPoolExecutor(5, 10; 3, TimeUnit.SECONDS, new ArrayBlockingQueue(50));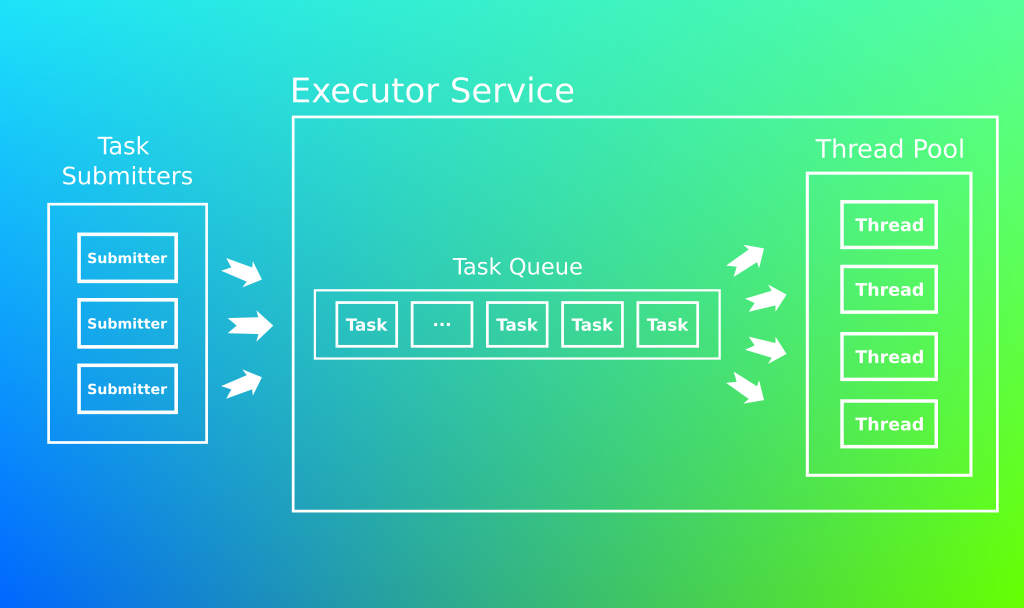
Les limites
Sa taille:
Reprenons notre exemple du supermarché:
En heure de pointe, il est toujours possible d’ouvrir des caisses pour traiter d’avantage de paiement, mais le magasin possède une surface finie!
Un pool est limité par sa taille et son hardware, sa scalabilité n’est pas infini!
Un pool de thread est un goulot d’étranglement, il peut aussi être vue comme un outils de Back-Pressure. Le dimensionnement d’un pool est un élément critique de votre application et doit porter toute votre attention! Une étude de la production est essentiel en tenant compte des pics de charge journaliers ainsi que des tests de charges. N’oubliez pas que la production reste malgré tout difficile à prédire.
Son empreinte mémoire:
Chaque thread possède sa propre pile d’exécution, multiplier les threads impacte la taille de la mémoire disponible pour les traitements métiers.
La concurrence:
Avoir plusieurs threads implique de prendre en compte des problématiques de concurrence comme les locks qui bloquent les traitements de la Jvm etc.
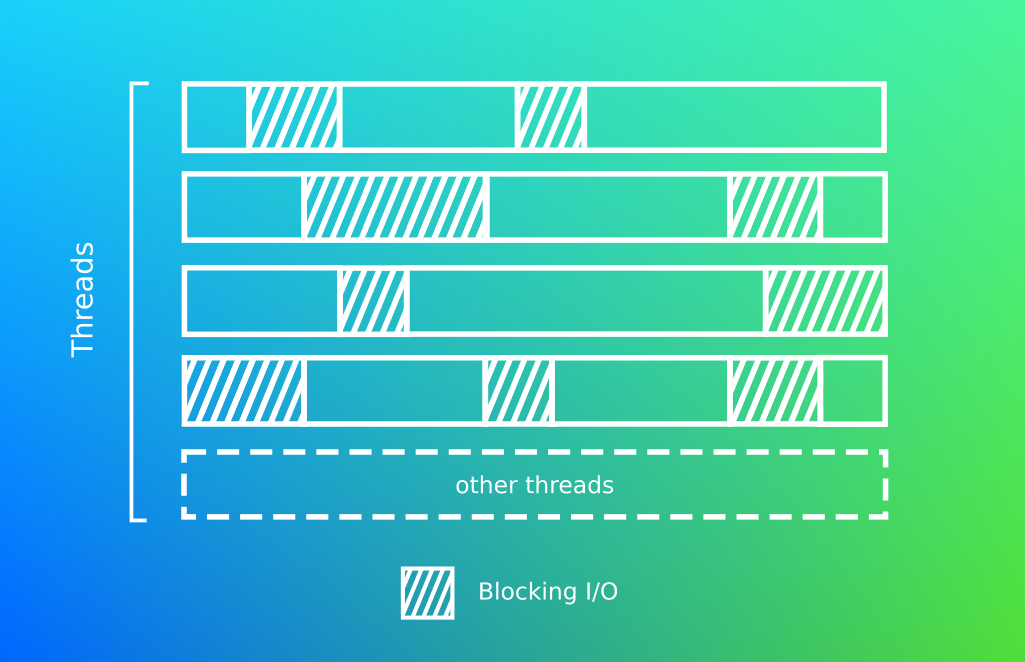
Mais que se passe t’il sous le capot?
Nous le savons en informatique les threads sont exécutés par le CPU et cela dans la limites des cœurs disponibles. Au delà, la machine émulera la parallélisation en exécutant alternativement ses processus et effectuera ce que l’on appelle des switchs de context.
Le switch de context:
C’est le nom donné à l’action du processeur lorsqu’il passe du traitement d’un thread à un autre.
Pour cela le CPU à besoin:
- de sauvegarder l’état du thread
- de changer ses pointeurs en mémoires
Cette opération n’est pas gratuite et ce n’est pas une opérations que l’on souhaite invoquer outre mesure !
La commande pidstat permet d’observer les commutations de contextes:
[baptiste@localhost ~]$ pidstat -w -d -t -p 3583 -h
Linux 5.9.16-200.fc33.x86_64 (localhost.localdomain) 28/12/2020 x86_64 (16 CPU)
Time UID TGID TID kB_rd/s kB_wr/s kB_ccwr/s iodelay cswch/s nvcswch/s Command
03:14:46 1000 - 3714 0,00 0,00 0,00 0 2,76 0,01 |__default I/O-1
03:14:46 1000 - 3715 0,00 0,00 0,00 0 2,76 0,02 |__default I/O-2
03:14:46 1000 - 3716 0,00 0,00 0,00 0 2,72 0,02 |__default I/O-3
03:14:46 1000 - 3717 0,00 0,00 0,00 0 2,76 0,02 |__default I/O-4
03:14:46 1000 - 3718 0,00 0,00 0,00 0 2,83 0,01 |__default I/O-5
03:14:46 1000 - 3719 0,00 0,00 0,00 0 6,34 0,46 |__default cswch/s Nombre total de commutation de contexte volontaire effectué par seconde. Une commutation de contexte volontaire est réalisée quand un traitement ne parvient pas à accéder à une ressource.
nvcswch/s Nombre total de commutation de contexte involontaire effectué par seconde. Une commutation de contexte involontaire est réalisée quand une tache lors de sa fenêtre d'éxecution est forcée de renoncer à son traitement.
Existe-t-il une architecture qui permet d’éviter ces problèmes ?
La réponse est oui et ce n’est pas une nouveauté ! Les applications avec interface graphique comme AWT/Swing et plus récemment NodeJs connaissent bien ces problématiques.
Le design pattern Reactor:
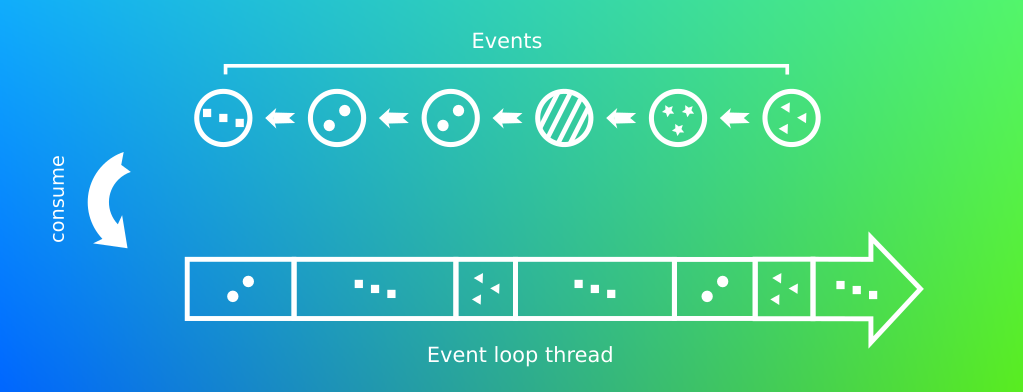
Ce pattern permet de traiter des événements les un à la suite des autres. Il s’agit d’une variante du pattern Observateur mais traitant des évènements de plusieurs sources. On le nomme autrement boucle de démultiplexage.
Pour mieux comprendre je vous propose de lire l’implémentation de Julien Ponges tiré du livre Vert.x in Action.
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentLinkedDeque;
import java.util.function.Consumer;
public final class EventLoop {
public static final class Event {
private final String key;
private final Object data;
public Event(String key, Object data) {
this.key = key;
this.data = data;
}
}
private final ConcurrentLinkedDeque<Event> events = new ConcurrentLinkedDeque<>();
private final ConcurrentHashMap<String, Consumer<Object>> handlers = new ConcurrentHashMap<>();
public EventLoop on(String key, Consumer<Object> handler) {
handlers.put(key, handler);
return this;
}
public void dispatch(Event event) {
events.add(event);
}
public void run() {
while (!(events.isEmpty() && Thread.interrupted())) {
if (!events.isEmpty()) {
Event event = events.pop();
if (handlers.containsKey(event.key)) {
handlers.get(event.key).accept(event.data);
} else {
System.err.println("No handler for key " + event.key);
}
}
}
}
public void stop() {
Thread.currentThread().interrupt();
}
public static void main(String[] args) {
EventLoop eventLoop = new EventLoop();
new Thread(() -> {
for (int n = 0; n < 6; n++) {
delay(1000);
eventLoop.dispatch(new EventLoop.Event("tick", n));
}
eventLoop.dispatch(new EventLoop.Event("stop", null));
}).start();
new Thread(() -> {
delay(2500);
eventLoop.dispatch(new EventLoop.Event("hello", "beautiful world"));
delay(800);
eventLoop.dispatch(new EventLoop.Event("hello", "beautiful universe"));
}).start();
eventLoop.dispatch(new EventLoop.Event("hello", "world!"));
eventLoop.dispatch(new EventLoop.Event("foo", "bar"));
eventLoop
.on("hello", s -> System.out.println("hello " + s))
.on("tick", n -> System.out.println("tick #" + n))
.on("stop", v -> eventLoop.stop())
.run();
System.out.println("Bye!");
}
private static void delay(long millis) {
try {
Thread.sleep(millis);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
Output:
hello world!
tick #0
No handler for key foo
tick #1
hello beautiful world
tick #2
hello beautiful universe
tick #3
tick #4
tick #5
Bye!Les taches sont traitées les une après les autres de manière séquentielle. Ce n’est pas un pattern sans failles ! Les traitements longs ne doivent pas être exécutés au sein de la boucle, cela reviendrait à bloquer tous les autres traitements!
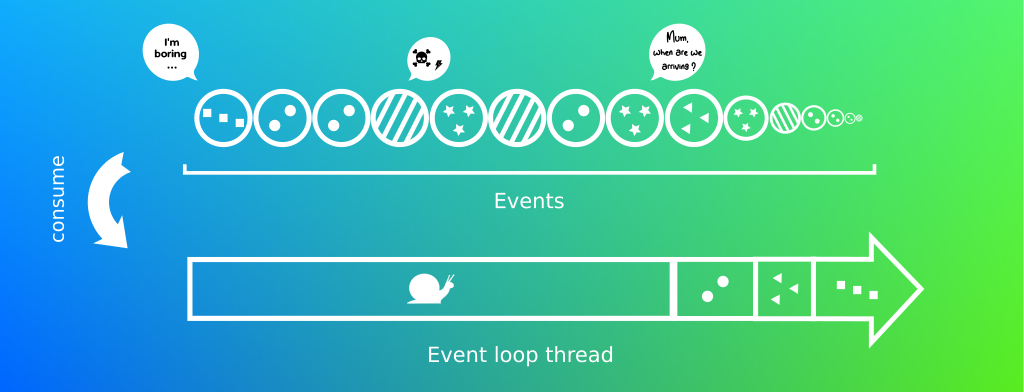
Soyons honnête je ne connais pas un seul programme ne possédant pas de longues taches bloquantes. L’idée est de les décomposer en taches courtes, mais cela n’est pas toujours possible! Les exemples ne manquent pas, les appels à une base de données, un appel à une API Rest tiers etc etc. Vert.x en grand seigneur laisse la possibilité d’utiliser des pools de threads plus conventionnels permettant d’exécuter ces longs traitements. Ils sont appelés les Workers.

Vert.x repose sur une variante de ce mécanisme, le pattern Multi-Reactor.
Vert.x améliore l’usage de ce pattern en multipliant le nombre d’events loop. Chacune d’entre elles sont associées à un cœur, permettant ainsi de résoudre la problématique de commutation de contexte. Son nombre peut varier et est en conséquence limité par l’architecture du processeur.
Pour y voir plus clair essayons de calculer le nombre maximum d’event loop pour ma machine:
[baptiste@localhost bin]$ lscpu
Architecture : x86_64
Processeur(s) : 16
Liste de processeur(s) en ligne : 0-15
Thread(s) par cœur : 2
Cœur(s) par socket : 8
Socket(s) : 1
Nœud(s) NUMA : 1Vert.x applique la rêgle suivante:
Nombre de processeurs * 2
ce qui donne dans mon cas: 16 * 2 = 32
C’est codé en une ligne ici
A noter que Vert.x est en quelque sorte, une sur-couche au célèbre framework Netty et facilite son usage.
mvn dependency:tree
...
[INFO] +- io.vertx:vertx-service-proxy:jar:4.0.2:compile
[INFO] | \- io.vertx:vertx-core:jar:4.0.2:compile
[INFO] | +- io.netty:netty-common:jar:4.1.52.Final:compile
[INFO] | +- io.netty:netty-buffer:jar:4.1.52.Final:compile
[INFO] | +- io.netty:netty-transport:jar:4.1.52.Final:compile
[INFO] | +- io.netty:netty-handler:jar:4.1.52.Final:compile
[INFO] | | \- io.netty:netty-codec:jar:4.1.52.Final:compile
[INFO] | +- io.netty:netty-handler-proxy:jar:4.1.52.Final:compile
[INFO] | | \- io.netty:netty-codec-socks:jar:4.1.52.Final:compile
[INFO] | +- io.netty:netty-codec-http:jar:4.1.52.Final:compile
[INFO] | +- io.netty:netty-codec-http2:jar:4.1.52.Final:compile
[INFO] | +- io.netty:netty-resolver:jar:4.1.52.Final:compile
[INFO] | \- io.netty:netty-resolver-dns:jar:4.1.52.Final:compile
[INFO] | \- io.netty:netty-codec-dns:jar:4.1.52.Final:compileCommençons par créer notre premier programme
import io.vertx.core.AbstractVerticle;
import io.vertx.core.DeploymentOptions;
import io.vertx.core.Promise;
import io.vertx.core.Vertx;
public class MainVerticle extends AbstractVerticle {
@Override
public void start(Promise<Void> startPromise) throws Exception {
vertx.createHttpServer().requestHandler(req -> {
req.response()
.putHeader("content-type", "text/plain")
.end("Hello from Vert.x!");
}).listen(8888, http -> {
if (http.succeeded()) {
startPromise.complete();
System.out.println("HTTP server started on port 8888");
} else {
startPromise.fail(http.cause());
}
});
}
}Dans ce programme je crée un serveur Http qui nous dit bonjour. Ce code étend un objet central de Vert.x, les Verticles.
Vert.x repose sur le pattern Actor Model.
Ce model a été conçu pour faciliter la conception d’application ayant de fortes contraintes concurrentielles.
Au même titre que la programmation objet considère que tout est objet, le model Acteur considère que tout est acteur.
Un acteur est une entité capable de calculer et qui en réponse d’un message, peut:
- envoyer un nombre fini de messages à d’autres acteurs ;
- créer un nombre fini de nouveaux acteurs ;
- spécifier le comportement à avoir lors de la prochaine réception de messages.
En résumé un Verticle est un acteur:
- qui communique avec les autres acteurs en envoyant des messages traités de manière asynchrone
- modifie uniquement son état (chacun dispose de son propre ClassLoader)
- définit un traitement pour un type de message
En apparté, il est extrêmement simple de multiplier les instances d’un Verticle.
Vertx.vertx().deployVerticle(FishDatabaseVerticle.class.getName(), new DeploymentOptions().setInstances(5));Comment envoyer un message ?
La communication entre les Verticles s’effectue via un bus d’événement partagé à l’ensemble des Verticles on y accède de la manière suivante:
EventBus eb = vertx.eventBus();Il est possible d’effectuer une communication de type point à point:
eventBus.send("fish.purchase", "Discus");Le message est envoyé à une instance cliente en suivant une stratégie de round robin.
De type Broadcast:
eventBus.publish("fish.sell", "Hi everyone, the Discus fish was sold");Le message est envoyé à l’ensemble des clients en écoute.
Point à point avec réponse:
eventBus.request("fish.purchase", "Scalare", ar -> {
if (ar.succeeded()) {
System.out.println(ar.result().body());
}
});MessageConsumer<String> consumer = eventBus.consumer("fish.purchase");
consumer.handler(message -> {
System.out.println("I have received a purchase: " + message.body());
message.reply("The price of the fish is " + priceMapping.get(message.body()));
});Les Handlers
Vous le trouverez partout et pour cause, il s’agit de définir un petit traitement qui sera ensuite envoyé dans l’event loop. Prenons l’exemple d’un traitement qui parse un long flux d’objet Json.
JsonParser.newParser(asyncFishFile).objectValueMode()
.handler(event -> {
if (Objects.nonNull(event.value())) {
Fish fish = event.mapTo(Fish.class);
System.out.println("Fish = " + fish);
}
})
.exceptionHandler(t -> {
t.printStackTrace();
asyncFishFile.close();
})
.endHandler(v -> {
System.out.println("Done!");
asyncFishFile.close();
});Vert.x est réactif
En regardant de plus prêt l’activité de la JVM d’une application au paradigme Impératif, vous remarquerez que votre application passe beaucoup de temps à attendre. C’est un gaspillage de ressource ! A contrario Vert.x utilise massivement l’asynchrone.
Les futures
Voici quelques opérateur de l’objet Future:
Map effectue une opération sur le future.
Recover est une sorte de catch, il permet de lancer un traitement en cas d'exception..
Eventualy est une sorte de finally, il est systématiquement appelé.
onSuccess, onFailure sont des systèmes de notification, ils ne modifient pas le future.
Bien d'autres méthodes
vertx.fileSystem().props("fishs.json")
.map(FileProps::size)
.recover(err -> Future.succeededFuture(0l))
.onSuccess(size -> System.out.println("File size = " + size))
.onFailure(res ->System.out.println("Failure: " + res.getCause().getMessage()));Vert.x dispose de sa propre implémentation des Futures, sachez qu’elle est entièrement compatible avec l’API CompletionStage fournit par le JDK et qu’il est possible d’utiliser RxJava.

RxJava est une implémentation Java de l’initiative ReactiveX qui propose de standardiser les API réactives quelque soit le langage.
Son application répond à l’ensemble des critères du Manifest Reactif:

Comment tester ?
De par sa conception avec le model Acteur, un traitement est isolé au sein de son Verticle, en revanche son coté asynchrone rend les choses légèrement plus compliqué. Pour palier ce problème Vert.x nous fournit plusieurs outils.
VertxTestContext:
Dans l’exemple ci-dessous, nous souhaitons vérifier que notre serveur http est correctement lancé.
@ExtendWith(VertxExtension.class)
class DatabaseVerticleDeploymentTest {
Vertx vertx = Vertx.vertx();
@Test
void it_should_start_database_verticle() throws Throwable {
VertxTestContext testContext = new VertxTestContext();
vertx.deployVerticle(new FishDatabaseVerticle())
.onSuccess(res -> testContext.completeNow()) (1)
.onFailure(res -> System.out.println("An error occur"));
assertThat(testContext.awaitCompletion(5, TimeUnit.SECONDS)).isTrue(); (2)
if (testContext.failed()) {
throw testContext.causeOfFailure(); (3)
}
}
}
(1) est l'instruction qui définit le succès de notre test.
(2) awaitCompletion vérifie que completeNow soit déclenché avant 5 secondes.
(3) dans le cas contraire le test sera en echec. Vert.x vous laisse l’usage de votre librairie d’assertion préféré, il suffira d’encapsuler votre vérification dans l’une des méthodes suivantes verify, succeeding ou failing du VertxTestContext.
@Test
void it_should_insert_fish(Vertx vertx, VertxTestContext testContext) {
String fishName = "Scalare";
WebClient client = WebClient.create(vertx);
client.post(PORT, HOST, APPLICATION_CONTEXT + "?name=" + fishName)
.as(BodyCodec.string())
.send(testContext.succeeding(response -> testContext.verify(() -> {
assertThat(response.body()).isNotBlank();
testContext.completeNow();
})));
}Les checkpoints:
Ce mécanisme permet de vérifier les traitements multiples en définissant un nombre de déclenchement à atteindre.
@Test
void it_should_get_existing_fish2(VertxTestContext testContext) {
String fish1 = "Discus";
String fish2 = "Scalare";
Checkpoint checkpoint = testContext.checkpoint(2); (1)
createFish(fish1).map(createFish(fish2)).onSuccess(nothing -> {
dbService.existFishByName(fish1, res -> {
if (res.succeeded()) {
checkpoint.flag(); (2)
}});
dbService.existFishByName(fish2, res -> {
if (res.succeeded()) {
checkpoint.flag(); (3)
}});
});
}
(1) Ici je déclare un compteur de deux unités
(2) (3) L'instruction flag va décompter une unité de son compteurEt si on codait une véritable application ?
Pour ceux qui me suivent, vous connaisez ma passion pour l’aquariophilie. Il s’agira cette fois d’une simple application répertoriant les poissons que j’ai pu acheter. Il s’agit d’une application toute simple exposant des opérations de type CRUD via une API Rest.
Faisons ensemble un tour de quelques fonctionnalités que j’ai pu utiliser.
Je lance mon application de la façon suivante:
[baptiste@localhost target]$ java -jar target/vertx-fishs-1.0.0-SNAPSHOT-fat.jarAvec un poids de
[baptiste@localhost target]$ ls -alhs | grep -i snapshot
24M -rw-rw-r--. 1 baptiste baptiste 24M 16 févr. 21:23 vertx-fishs-1.0.0-SNAPSHOT-fat.jarEt une empreinte mémoire de
[baptiste@localhost target]$ jcmd 5780 GC.heap_info
5780:
garbage-first heap total 516096K, used 62101K [0x000000060d200000, 0x0000000800000000)
region size 2048K, 29 young (59392K), 4 survivors (8192K)
Metaspace used 32591K, capacity 33798K, committed 33920K, reserved 1079296K
class space used 3700K, capacity 4192K, committed 4224K, reserved 1048576KOpenApi
Le contrat de mon API est déclarée dans un fichier yaml.
openapi: 3.0.0
info:
version: 1.0.0
title: Swagger Fishstore
license:
name: MIT
servers:
- url: http://localhost:8080/v1
paths:
/fishs:
get:
summary: List fishs
operationId: listFishs
tags:
- fishs
parameters:
- name: name
in: query
description: Restrict fish detail by name
required: false
schema:
type: string
responses:
200:
description: List of fishs
content:
application/json:
schema:
$ref: "#/components/schemas/Fishs"
...
components:
schemas:
Fish:
type: object
required:
- id
- name
properties:
id:
type: integer
format: int64
name:
type: string
tag:
type: string
Fishs:
type: array
items:
$ref: "#/components/schemas/Fish"Coté Java l’application source ce fichier de la façon suivante:
RouterBuilder.create(vertx, "src/main/resources/webroot/fishStore.yaml").onComplete(ar -> {
if (ar.succeeded()) {
Router global = this.getOpenApiRouter(ar.result());
vertx.createHttpServer()
.requestHandler(global)
.onSuccess(res -> {});
}Et je route mes contextes vers mes opérations en base de données.
private Router getOpenApiRouter(RouterBuilder routerBuilder) {
routerBuilder
.operation("listFishs")
.handler(this::allFishsHandler)
.failureHandler(this::faillureHandler);
routerBuilder.operation("createFish")
.handler(this::fishCreateHandler)
.failureHandler(this::faillureHandler);
...
Router global = Router.router(vertx);
Router generated = routerBuilder.createRouter();
global.mountSubRouter("v1", generated);En plus de pouvoir y brancher un Swagger, utiliser OpenAPI facilite la validation des paramètres et l’intégration d’un système d’authentification.
HealthCheck
Pour définir un HealthCheck digne de ce nom, il faut qu’il soit en mesure de vérifier que la base de données est disponible. Pour cela l’API de Health monitoring de Vert.x permet de facilement ajouter autant de contrôles que vous le souhaitez.
private HealthCheckHandler healthHandler() {
HealthCheckHandler healthCheckHandler = HealthCheckHandler.create(vertx);
healthCheckHandler.register("check-database", promise -> {
dbService.isAvailable(res -> {
promise.complete(res.succeeded() ? Status.OK() : Status.KO());
});
});
return healthCheckHandler;
}Le résultat est consultable sur la route que vous avez définit et retourne un Json.
Elle est composée de deux parties:
- Une liste de contrôles additionnels, ici la présence de la base de données
- Un status global de l’application, produit cartésien des vérifications (status et outcome sont calculés de la même façon)
{"status":"UP","checks":[{"id":"check-database","status":"UP"}],"outcome":"UP"}L’API de Health est entièrement compatible avec les normes du Cloud. Dans mon cas je me suis contenté d’implémenter un seul HealthCheck mais rien ne vous empèche d’implémenter un contexte pour le Live et Ready ness.
Metrics
Pour information Vert.x utilise deux objects pour se lancer, un Launcher et un Verticle. Par défaut vous n’avez rien à faire, pour la mise en place de Micrometer nous avons besoin de les implémenter.
public class FishLauncher extends Launcher {
public static void main(String[] args) {
new FishLauncher().dispatch(args);
}
@Override
public void beforeStartingVertx(VertxOptions options) {
// METRICS
options.setMetricsOptions(new MicrometerMetricsOptions()
.setPrometheusOptions(new VertxPrometheusOptions().setEnabled(true)
.setStartEmbeddedServer(true)
.setEmbeddedServerOptions(new HttpServerOptions().setPort(8081))
.setEmbeddedServerEndpoint("/metrics"))
.setEnabled(true));
}
...
}Ici je décide d’utiliser Micrometer (plusieurs implémentations sont disponibles). Sa mise en place s’effectue à l’exterieur d’un Verticle.
# HELP vertx_http_server_request_bytes Size of requests in bytes
# TYPE vertx_http_server_request_bytes
histogram vertx_http_server_request_bytes_bucket{method="GET",le="1.0",} 3.0
...
vertx_pool_usage_seconds_count{pool_type="worker",} 1617.0
vertx_pool_usage_seconds_sum{pool_type="worker",} 1.147378429
# HELP vertx_pool_usage_seconds_max Time using a resource
# TYPE vertx_pool_usage_seconds_max gauge vertx_pool_usage_seconds_max{pool_type="datasource",} 0.0 vertx_pool_usage_seconds_max{pool_type="worker",} 0.001223763
# HELP vertx_eventbus_delivered_total Number of messages delivered to handlers
# TYPE vertx_eventbus_delivered_total counter
vertx_eventbus_delivered_total{side="local",} 2.0
# HELP vertx_eventbus_processed_total Number of processed messages
# TYPE vertx_eventbus_processed_total counter
vertx_eventbus_processed_total{side="local",} 2.0
# HELP vertx_pool_completed_total Number of elements done with the resource
# TYPE vertx_pool_completed_total counter
vertx_pool_completed_total{pool_type="datasource",} 2.0
vertx_pool_completed_total{pool_type="worker",} 1617.0Et voila un flux tout beau tout propre prêt à être exploité par Prometheus !
Vert.x Shell
En bonus un petit service qui fait toujours plaisirs, une CLI pour interagir votre application!
ShellService service = ShellService.create(vertx,
new ShellServiceOptions().setTelnetOptions(
new TelnetTermOptions().
setHost("localhost").
setPort(4000)
)
);
service.start();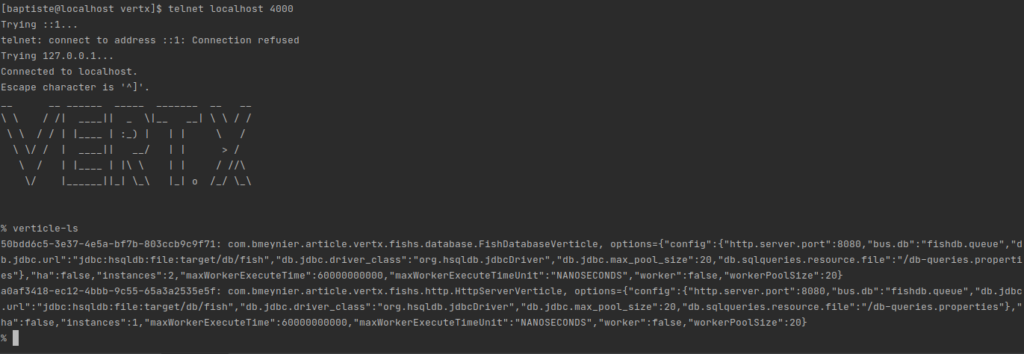
Je vous invite a consulter l’intégralité du code sur GitLab, vous y trouverez la partie persistance, l’utilisation de Service proxy, la gestion des confs le Hot Reload etc etc.

Code source
Conclusion

Les questions que tu te poses
C’est un framework très bas niveau compliqué à utiliser ?
Non, ces concepts sont différents de ceux utilisés dans le monde du backend Java standard, mais son API est particulièrement riche et agréable à utiliser. Un développeur Front-End ne serait absolument pas dépaysé. Vous trouverez énormément de documentation sur le net.
Est-il possible d’utiliser Spring et Vert.x en meme temps ?
Oui n’oubliez pas qu’il s’agit d’une boite à outils et non d’un framework, vous trouverez facilement des tutoriaux sur le net.
Est il possible d’utiliser un Spring Config Server Store ?
Oui, direction la documentation officielle.
Pour quel genre d’application est il pertinent d’utiliser Vert.x ?
Vert.x excèle dans le traitement des flux volumineux. je vous invite à consulter sa fonctionnalité de parsing des Streams et son API de traitement de fichiers.
Dois-je utiliser Vert.x si la base de données de mon application est de type Sql relationnel ?
Vous l’avez vu dans l’exemple, il est tout à fait possible d’utiliser JDBC avec Vert.x, cependant n’oubliez pas que JDBC n’en reste pas moins une API bloquante. A noter que pour palier ce problème Vert.x déploiera un pool de type worker.
Est il possible de convertir son application Vert.x en code natif via GraalVM?
Je n’ai jamais entendu parler de Vert.x qui l’utilise ?
Vert.x est très largement utilisé, voici une liste non exhaustive:

https://twitter.com/clementplop
https://twitter.com/tsegismont
https://twitter.com/vertx_project
Sources
https://www.reactivemanifesto.org/fr
https://www.manning.com/books/vertx-in-action
https://fr.wikipedia.org/wiki/Mod%C3%A8le_d%27acteur
https://www.youtube.com/watch?v=8aGhZQkoFbQ&ab_channel=JSConf
https://www.youtube.com/watch?v=3_CRKfs4Zzo&ab_channel=OracleDevelopers
https://github.com/burrsutter/vertx_ha_demo