


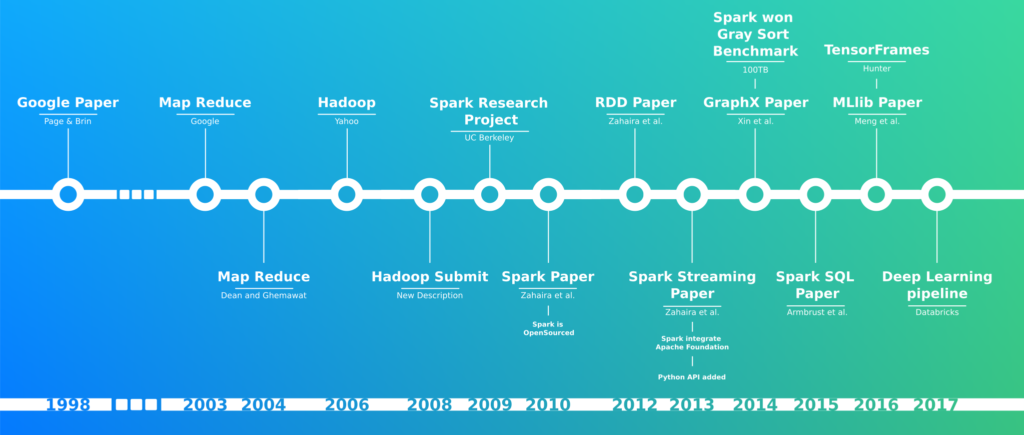
Un peu d’histoire
Infrastructure
Big data = gros disque ?
HDD : est un boîtier contenant une série de plateaux recouverts d’un revêtement ferromagnétique. La direction de l’aimantation représente les éléments binaires individuels. Les données sont lues et écrites par une tête (similaire à ce que peu faire une platine vinyle avec un disque) qui se déplace extrêmement rapidement d’une zone du disque à l’autre. Étant donné que toutes ces pièces sont « mécaniques », le disque dur est le composant le plus lent de tout ordinateur et le plus fragile.
SSD : ces types de disques stockent des informations sur une mémoire flash composée de cellules de mémoire individuelles stockant des éléments binaires qui sont instantanément accessibles par le contrôleur.
C’est quoi un controleur disque?
Il s’agit d’un ensemble électronique qui contrôle la mécanique d’un disque dur. Son rôle est de piloter les moteurs de rotation, de positionner les têtes de lecture/enregistrement, et d’interpréter les signaux électriques reçus de ces têtes pour les convertir en données exploitables ou d’enregistrer des données à un emplacement particulier de la surface des disques composant le disque dur.
Evolution du stockage à travers le temps:
| HDD | SSD | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Années | 1956 | 1970 | 1980 | 1990 | 2000 | 2010 | 2020 | ||
| Format | 50 plateaux de 24″ | 5,25” | 3,5″ | 3,5″ | 2,5″ | 2,5″ | 2,5″ | ||
| Volume Max | 5 MB | 60 MB | 446 MB | 1000 MB | 18 000 MB | 4 000 000 MB | 20 000 000 MB | 4 000 000 MB | |
| Débit théorique | 8 800 caractères/s | 625 Ko/s | 0.7 Mb/s | 9.5 Mb/s | 110 Mb/s | 200Mb/s | 500 Mb/s | ||
| Prix pour 1 Mo | 1mo 10 000 $ | 1mo 193 $ | 1 mo 9 $ | 1 Go 2 € | 1 Go 0.10€ | 1Go 0.02€ | 1Go 0.15€ | ||
| Rapport Volume Max/Débit | 713.6 | 1428 | 1894 | 36363 | 100000 | 8000 |

Dans le cas de stockage sur fichier il vaut mieux privilégier les petits disques durs plus précisément ceux ayant le meilleur ratio volume/débit.
Note: il est possible de connaitre le type de disque dur de votre machine via la commande “lsblk -d -o name,rota” (HDD rota=1, SSD rota=0)
Quelques exemples de Stockages:

permet de stocker des fichiers bruts ou structurés via le format Parquet.

est un site d’hébergement de fichiers. Son API est accéssible via REST / SOAP ou encore BitTorent.

est la Rolls Royces des systémes de gestion de base de données(NoSQL). Elle est conçu pour gérer des quantités massives de données sur un grand nombre de serveurs, assurant une haute disponibilité en éliminant les points de défaillance. Il permet de répartir les données sur plusieurs centres, avec une réplication asynchrone sans nœud maître et une faible latence pour les opérations de tous les clients.
Ce qu’il faut retenir de la partie Stockage:
Intéressez-vous au controleur de votre disque et rien ne sert de prendre des disques de trop grand volume le plus important reste le ratio volume/débit.
Et le Réseaux dans tout ça ?
La carte réseau assure l’interface entre l’équipement et les machines connectées sur le même réseau. Les débits s’expriment généralement en Mbit/s (mégabites par seconde : millions de bits par seconde).
Les débits actuels du standard Ethernet sont :
- 10 Mbit/s ;
- 100 Mbit/s (Fast Ethernet) ;
- 1 000 Mbit/s parfois également noté 1 Gbit/s (Gigabit Ethernet) ;
- 10 000 Mbit/s (10 Gigabit Ethernet).
Y-a-t’il des éléments à prendre en compte entre réseau et disques ?
Il est important de garder en tête que le controleur réseaux est une contraintes.
Supposons que nous disposons de l’Ethernet 1Gb en Full Duplex (émission et réception simultanée).
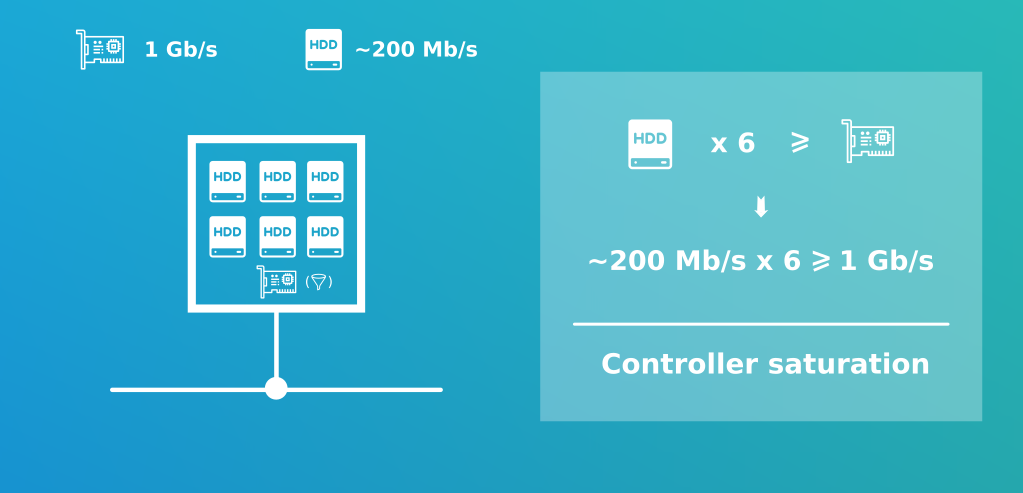
Note: Spark préconise un éthernet de 10 GB
Et si on mettait nos noeuds sur un gros clusters avec des VM ou des conteneurs ?
La virtualisation tout comme la conteneurisation est une abstraction du matériel. En choisissant cette méthode nous perdons le contrôle de notre infrastructure. De plus nous sommes toujours contraint aux mêmes problématiques du goulot d’étranglement du controleur réseaux
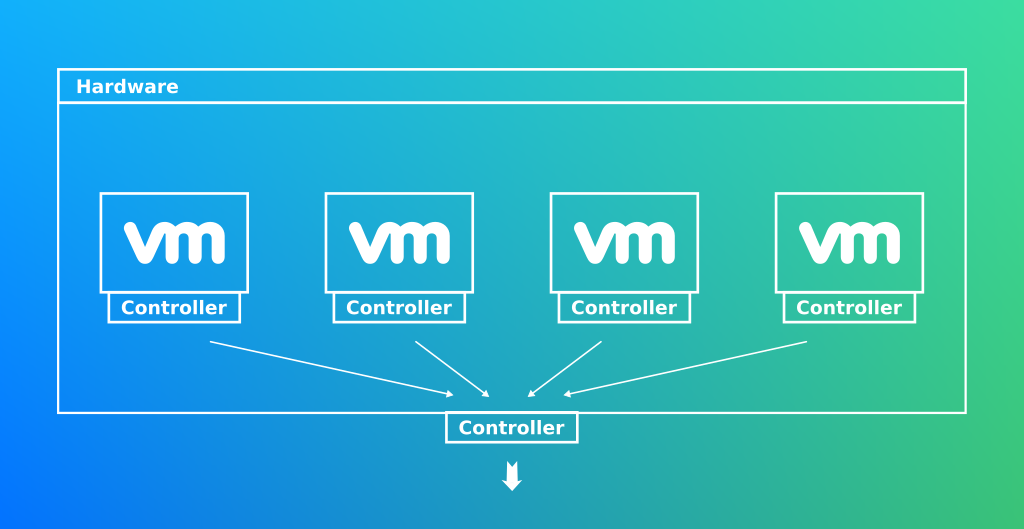
Note: Lorsque qu’un applicatif hébergé sur VM à besoin d’accéder à du matériel, l’OS hébergé opère un certains nombre de convertions avec son OS host. Cela implique de la latence et du travail CPU.
L’idée est d’avoir une architecture composée de petites machines dites “jetables”. Ne jamais acheter de grosses machines !
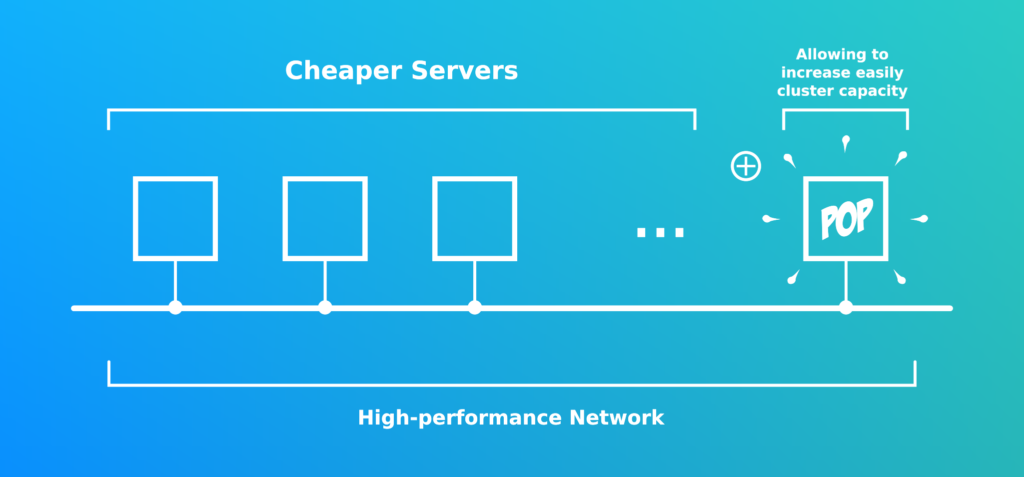
Note: Il est recommandé de désactiver le swap
Mais comment accéder à la données ?
Il existe plusieurs outils pour exploiter de la données Big Data.
- ETL (Apache Pig, Talend, …)
- Framework imposant le pattern Actor (VertX, Spring Reactor, Akka)
- Streaming (Kafka, Flink)
- Et celui qui nous intéresse, Spark !

Note: Il est important de comprendre que le stockage et le calcul vont de paire comme Bonnie and Clyde, Tintin et Milou… L’un ne va pas sans l’autre!
L’architecture de Spark se repose sur le calcul distribué
L’idée de Spark est de répartir la charge de calcul et mémoire, sur l’ensemble des machines. Attention, toutes les opérations ne sont pas toujours décomposables. Elle doit être commutative (x*y = y*x) et associative ((x*y)*z = x*(y*z).
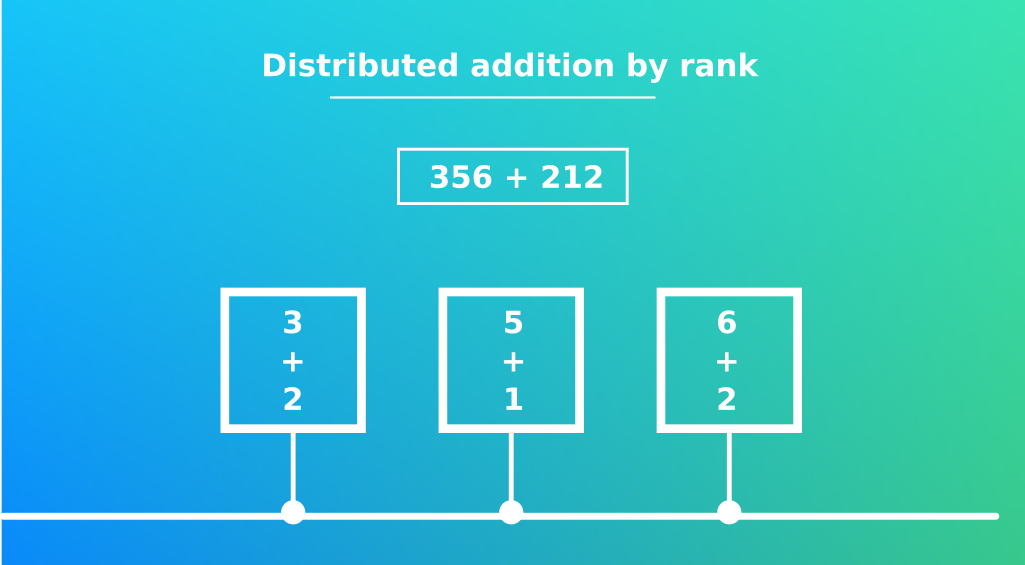
Pour illustrer nos propos prenons l’exemple de l’addition 351 + 128 et appliquons la méthode de calcul par rang (centaines, dizaines, unités).
Une génération de rapport trop gourmande:
Je suis dans une entreprise qui génère des rapports nécéssitant une empreinte mémoire de 64GB. Je dispose d’une infrastructure composée d’un rac de 128 GB sur lequel j’ai 2 instances (2 * 64) . Tout ce passe pour le mieux, jusqu’au jour ou le métier demande de générer d’avantage de données. Que dois-je faire ? Acheter un nouveau rac plus puissant ?
L’option du parallélisme:
Je décide plutot d’acheter 10 machines de 16 GB de RAM. Ce qui nous permettra de générer des rapports ayant une empreinte de 160 GB. Plutôt que d’avoir une seule grosse machine avec 120Gb ! Spark répartit le calcul et l’empreinte mémoire !
Note: Ne pas oublier que la scalabilité verticale est rarement la solution, au contraire dans la grande majorité des cas elle vous causera des problèmes!
Cette fois les contraintes matériels ne sont pas les mêmes, c’est la RAM qu’il faut favoriser.
Quelques exemples d’architecture:
- La plus courante: 1 cluster Spark + 1 cluster de stockage
- Ségreguée: 1 cluster Spark pour l’insertion + 1 cluster Spark de report + 1 cluster de stockage
- La plus performante: 1 cluster mutualisant Spark et Stockage (Cassandra). Elle nécessite des noeuds disposant de beaucoup de RAM et de très bon disques.
Ce qu’il faut retenir de la partie calcul:
Tout comme le stockage de bons équipement réseaux sont nécéssaires. Cette partie nécessite également de la RAM pas nécessairement en gros volume, mais répliquée plusieurs fois.
Les composants
Et si on suivait le cycle de vie d’une requête Spark ?
Pour mieux comprendre l’architecture de Spark nous nous baserons sur l’execution d’un code permettant de classer par ordre décroissant les mot les plus utilisés contenus dans un roman d’Emile Zola:
sc.textFile("/home/baptiste/Workspace/ventreDeParis.txt")
.flatMap(text => text.split(" "))
.filter(word => word.length !=0)
.map(word => word.replaceAll(",",""))
.map({ word => (word, 1) })
.reduceByKey( _ + _ )
.sortBy(t => t._2,false)
.collect()Spark utilise une architecture leader/follower. La soumission d’une requête s’effectue depuis le Maitre, par exemple via le Spark Shell (1).
Une fois soumis le code est envoyé au Driver(2). Il s’agit d’une application Java indépendante ayant pour but d’organiser le travail des followers à travers le réseau. C’est en quelques sorte le cerveau de notre architecture.
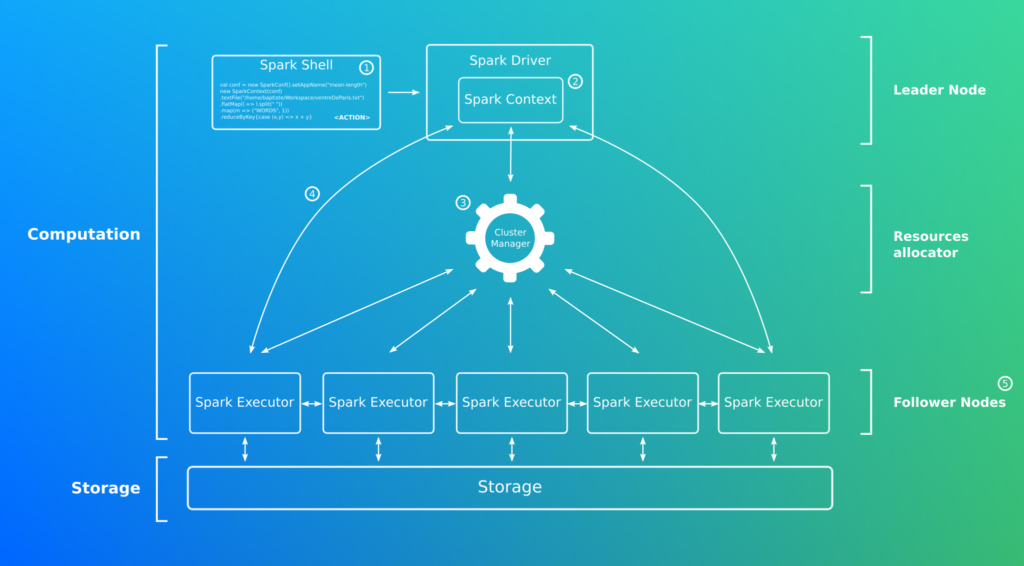
Note: le master pièce maitresse de l’architecture Spark en est aussi son SPOF.
Le Spark Context
Il s’agit du point d’entrée de Spark, il permet de:
- Se connecter à l’environnement d’éxecution Spark
- Récupérer le status de l’application Spark
- Annuler un Job/Stage
- Lancer un Job de manière synchronizé ou non
- Allouer programmatiquement des ressources
- Décomposer le code en unités de traitement plus petites
- Manager des RDD
- …
C’est quoi un RDD ?
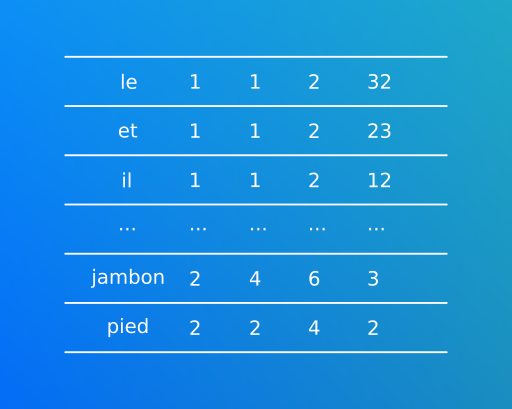
C’est l’objet de base que vous utiliserez tout le temps! Il signifie Resilient Distributed Datasets, c’est une collection de données redondée et distribuée à travers les noeuds d’executions. Si son mécanisme est compliqué, son apparence est simple il s’agit la plupart du temps d’un tableau multi colonnes:
RDD est par définition:
- In-memory (stocké en ram)
- Immuable (pour pouvoir être traité de manière concurrente)
- Lazy (nous détaillerons ce comportement plus tard)
Note: un RDD ne possède pas de nom de colonne
Tu nous parles de Job/Stage, mais qu’est ce que c’est ?
Une fois la requête soumise, le Spark Context va décomposer le code en unités d’exécution plus petites pour faciliter sa distribution.
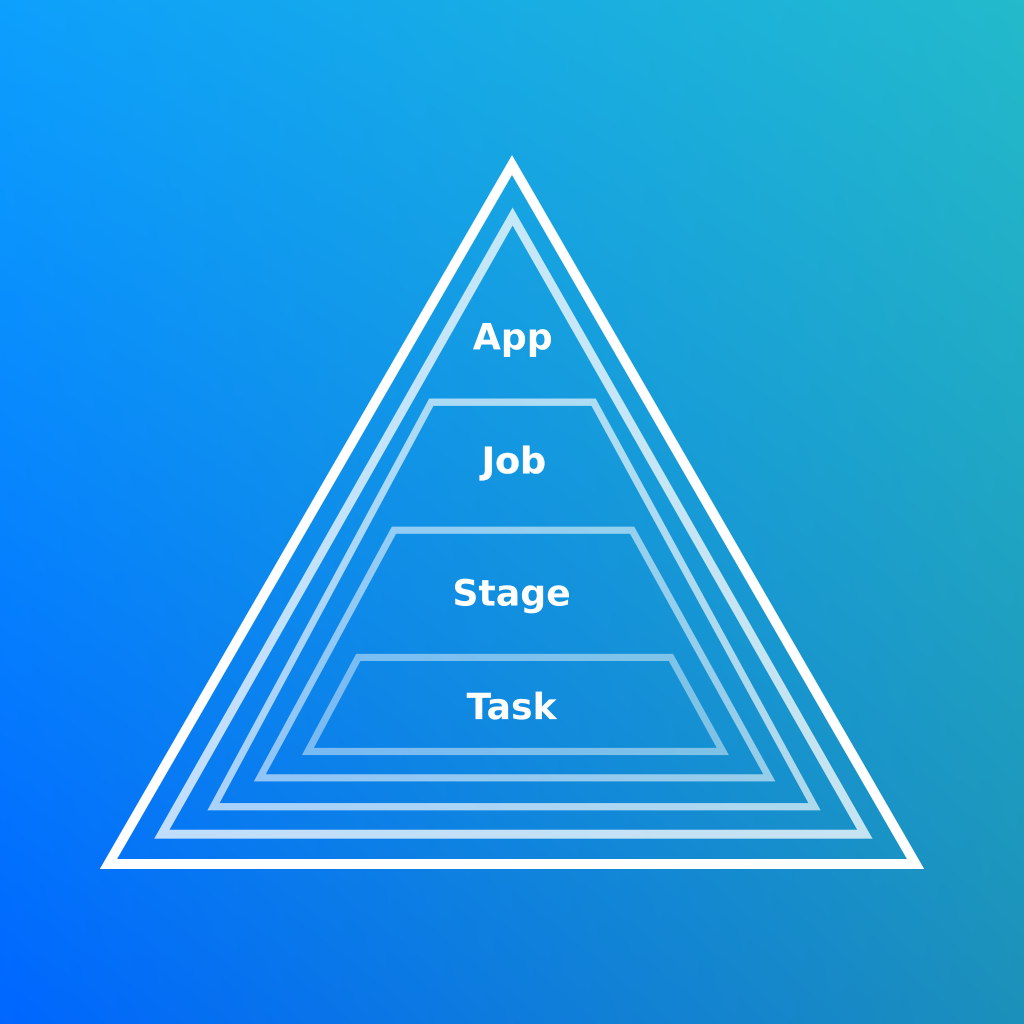
L’Application est au sommet de la hierarchie, il s’agit du programme que vous avez demandé d’executer.
Le Job correspond à l’execution d’une instruction.
Le Stage est une partie de l’execution d’une instruction (Job).
La Task est la granularité la plus basse dans Spark, il s’agit de tâches qui seront executées localement par un unique executeur.
Directed Acyclic Graph (DAG)
C’est lui qui est chargé de découper le Job Spark en unités d’execution.
[D]irected: est une sequence avec un début et une fin
[A]cyclic: qui ne possède pas de cycle
[G]raph: est un ensemble d’états et de transitions
Reprenons notre Job
Il existe deux types d’opérations, les transformations et les actions.
sc.textFile("/home/baptiste/Workspace/ventreDeParis.txt")
.flatMap(text => text.split(" ")) <== Transformation
.filter(word => word.length !=0) <== Transformation
.map(word => word.replaceAll(",","")) <== Transformation
.map(word => (word, 1)) <== Transformation
.reduceByKey( _ + _ ) <== Transformation
.sortBy(t => t._2,false) <== Transformation
.collect() <== ActionTransformations
Cette opération est dites “Lazy”. Les transformations sont d’abord stockées dans le DAG, puis évaluées au moment de l’execution d’une action.
Voici quelques exemples de transformations:
- flatMap: cette fonction retourne plusieurs elements pour une seule entrée fournie par le RDD.
rdd.flatMap(text => text.split(" "))
Je sépare le contenu du chapitre en fonction des espaces pour avoir une liste de mots.
- filter: filtre la donnée en tenant compte d’une condition
rdd.filter(word => word.length !=0)
Je supprime les chaines vides.
- map: applique une fonction de transformation à la donnée.
Dans ce RDD de mots, je retire toutes les virgules.
rdd.map(word => word.replaceAll(",",""))
Note: L’expression spécifiée à l’interieur de la fonction map est une fonction sans nom appelée lambda ou fonction anonyme.
- reduceByKey: regroupe les clefs identiques et applique une fonction sur leurs valeurs.
rdd.reduceByKey( _ + _ )
Note: Ici une notation scala, le underscore permet d’omettre la déclaration de la variable en entrée
- sortByKey: classe une collection de type clef/valeur (par défaut la clef est classée de manière ascendante).
rdd.sortBy(t=>t._2,false)
Ici je trie en fonction de la valeur de manière descentante.
Vous trouverez la liste exhaustive des transformations ici.
Actions
Il s’agit d’une opération qui s’éxecute immediatement.
Note: Pendant que la Transformation retourne un RDD, les Actions retournent du langage natif.
- Collect: retourne tous les éléments contenus dans le RDD.
rdd.collect()
Autres exemples:
- Count: compte le nombre d’éléments présents.
num = sc.parallelize([1,2,3,4,2])num.count() # output : 5
- First: Retourne le premier élément.
num.first() # output : 1
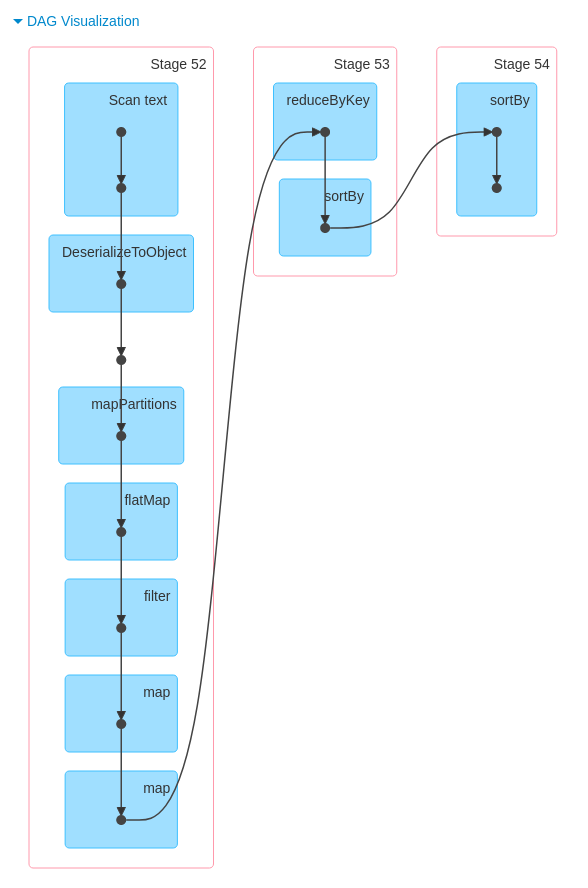
DAG associé au Job:
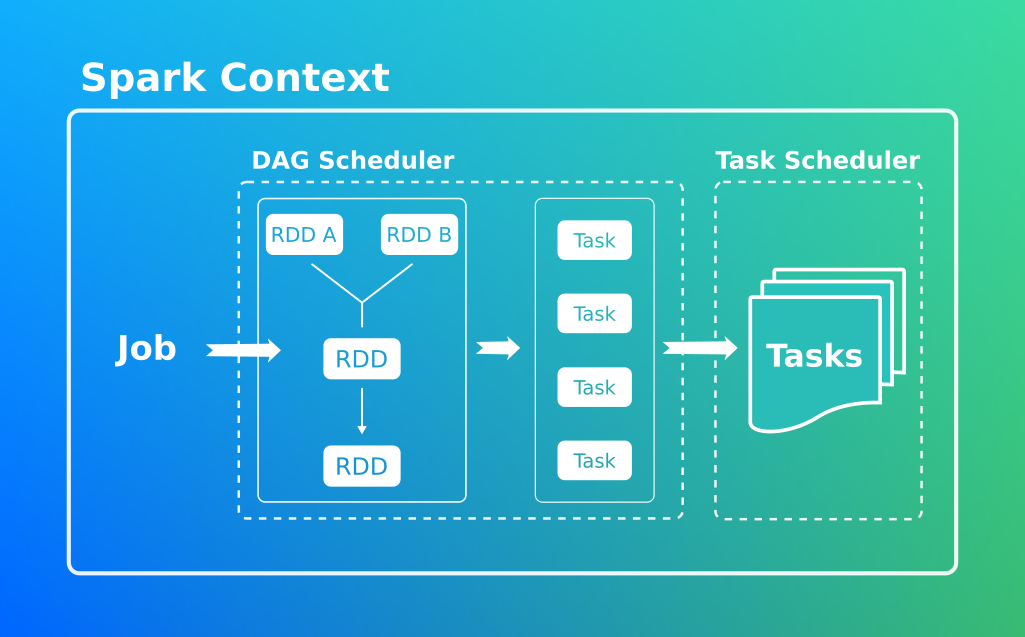
Task Scheduler
Il s’agit de l’intermédiaire entre le Leader et cluster manager. C’est lui qui envoie les taches générées par le DAG vers le cluster manager, il est également chargé de gérer leurs cycles de vie (les rejouer en cas d’échec) et temporiser en cas de besoin.
Cluster manager
Le Cluster managers est responsable de l’allocation/désallocation des ressources au sein du cluster Spark nécéssaire à un Job Spark. Il s’agit d’un service totalement découplé de Spark.

Pour les petits clusters (moins de 100 machines). Le master doit être couplé avec un Zookeeper.

Excellent cluster manager, permet d’orchestrer les grands parcs

L’orchestrateur d’Hadoop est compatible Spark

.
De nombreux providers Cloud proposent cette solution, elle à l’avantage de rendre l’application plus portable. Il faudra cependant préter attention aux IO.
.
Worker Node
La tache arrive enfin à bon port! C’est le worker qui interroge la couche stockage de votre application. La RAM va traiter la tache et générer une partition d’un RDD. Cette mémoire sert aussi à stocker en cache les RDD (Spark peut dans certains cas persister les RDD sur le disque). Une fois traité le résultat est renvoyé au Leader.
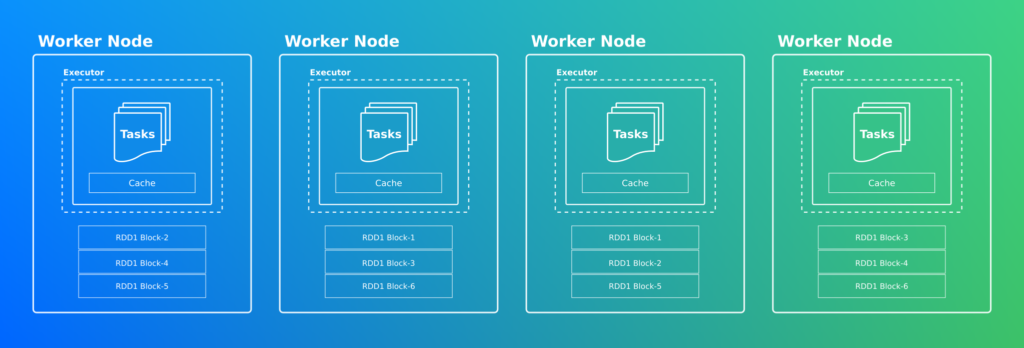
Les risques du calcul distribué
Nous l’avions évoqué plus haut, les IO doivent concentrer toute notre attention, surtout lorsque nous écrivons une requête Spark.
Le Shuffling
L’un des principaux risque d’un traitement Spark est le Shuffle. Illustrons ce terme avec un RDD stockant des informations sur des animaux.
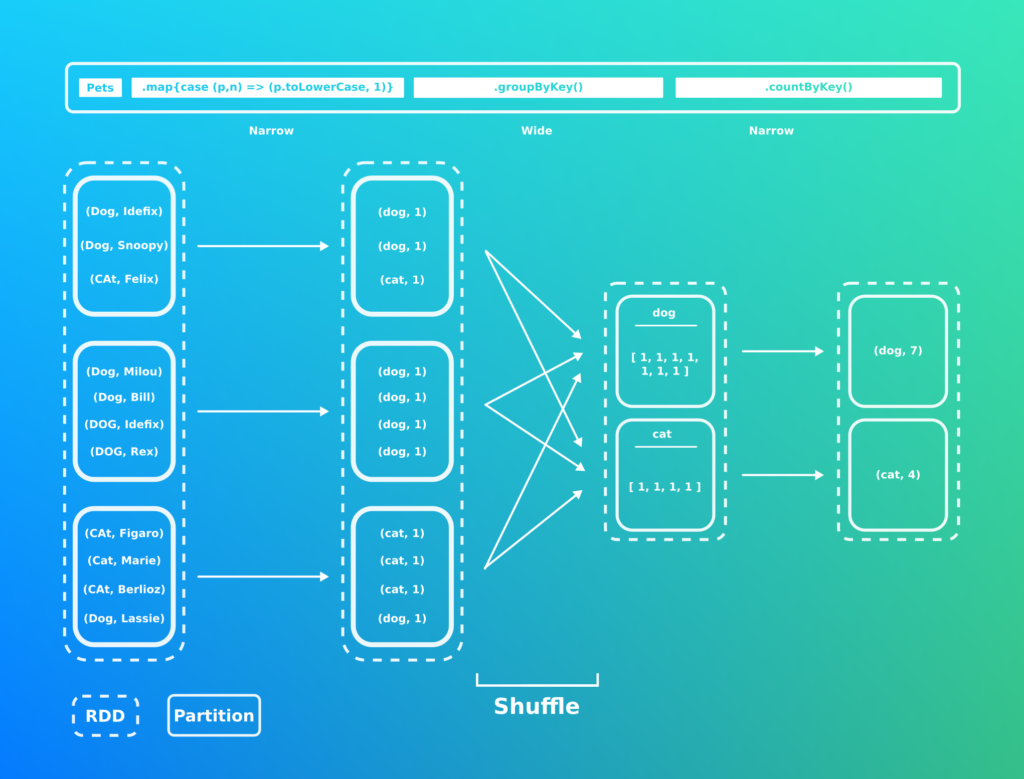
Le shuffle est le fait de devoir remixer des données et ainsi soliciter le réseau. Cette opération doit être à tout prix minimisé en modifiant notre requête Spark.
Comme vous avez pu le voir sur le schéma il existe 2 types d’opérations:
- Narrow: l’opération n’implique qu’une seule partition parente pour créer le nouveau RDD. Il s’agit de la plus rapide/prévisible des opérations. (Map, Filter, Union, …)
- Wide: est une opération qui s’applique sur plusieurs partitions parentes et implique un fort malaxage des données. Il est important de l’utiliser avec précaution (GroupByKey).
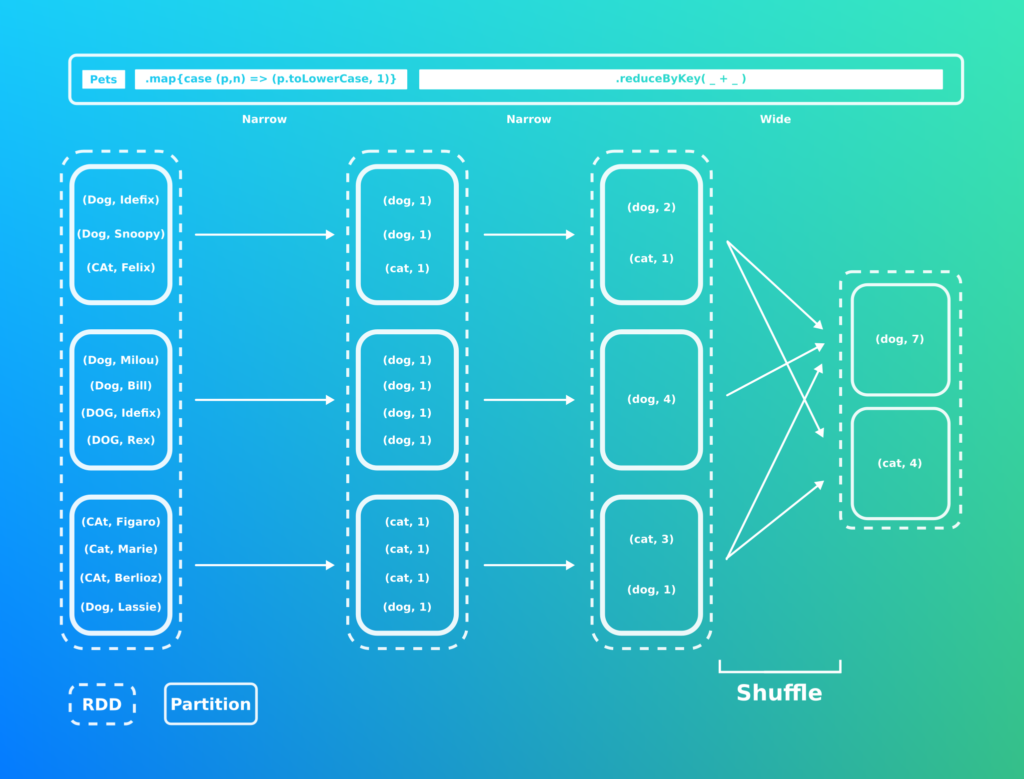
Note: dans le cas d’une architecture ayant un executeur partagé avec un noeud Cassandra le shuffling n’existe plus !
Cette requête est moins couteuse en IO réseaux puisque l’opération de regroupement est effectuée une première fois au niveau de la partition. Vous remarquerez l’usage du pattern Map Reduce.
Les Reduces:
Prenons le prototype le plus simple de la réduction.
def reduce(f: (T, T) => T): T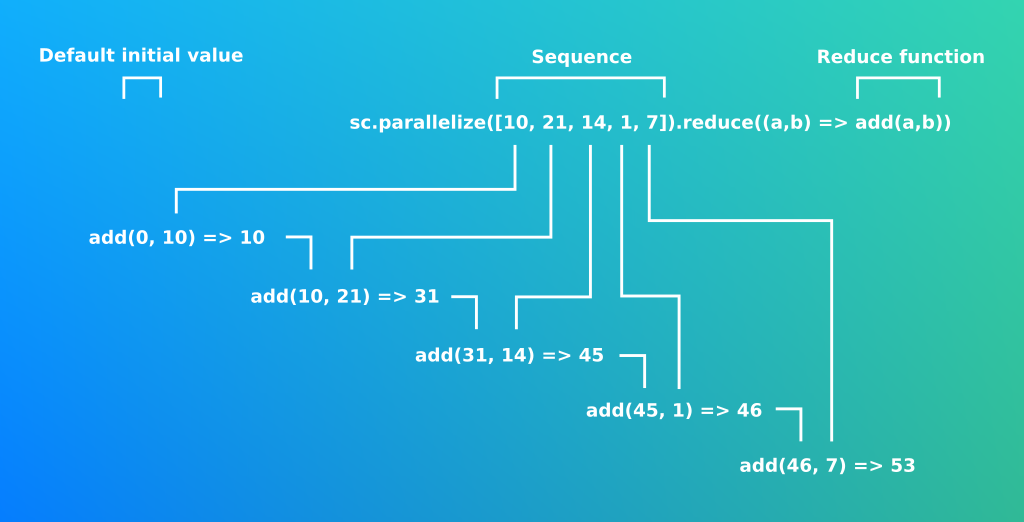
Le calcul distribué impose l’usage de fonctions commutatives et associatives, que doit respecter la fonction de réduction. En d’autre terme cela signifie que quelque soit l’ordre de la séquence le résultat sera identique. Le mécanisme de réduction repose également sur le concept d’accumulation et de récurcivité terminale.
Note: il est possible d’implémenter son propre accumulateur via l’interface AccumulatorV2
Requests as Design
Aussi appelé Query First Design, l’idée est de concevoir un modèles de données en fonction d’une requête que l’on souhaite effectuer (en tenant compte du shuffling). Ceci implique de multiplier les modèles de données au sein de votre stockage. Il est impossible de définir un modèle de données générique permettant de traiter de manière optimisé tous les cas d’utilisations.
Comment faire ?
- Penser son modèle de données en fonction de la requête, réfléchir au positionnement des clefs de partitions pour limiter le shuffle, etc.
- Insérer la donnée
- nettoyer (retirer les doublons, mettre en minuscule, retirer les accents, la ponctuation, certains mots inutiles, …)
- valider (vérifier que toutes les données obligatoires sont présentes, quelles sont cohérentes avec votre métier, …)
- transformer (pour être conforme à votre modèle de données)
- Rédiger la requête pour votre rapport (normalement c’est le plus simple, le plus gros du travail a été fait précédemment)
Et si on s’y mettait ?
Spark dispose de deux modes, le mode Cluster que nous venons de voir et le mode Local que nous allons utiliser ici/
Installation
[baptiste@fedora ~] curl -s "https://get.sdkman.io" | bash
[baptiste@fedora ~] sdk install java 11.0.11.hs-adpt
[baptiste@fedora ~] sdk install scala 2.13.5
[baptiste@fedora ~] sdk install sbt
[baptiste@fedora ~] sdk install spark
[baptiste@fedora ~] spark-shell
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://fedora:4040
Spark context available as 'sc' (master = local[*], app id = local-1623176900967).
Spark session available as 'spark'.
Welcome to
____ __
/ __/_ ___ ____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/____/ .__/\_,_/_/ /_/\_\ version 3.1.1
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.11)
Type in expressions to have them evaluated.
Type :help for more information.
scala>[baptiste@fedora current]$ tree .
.
├── bin
│ ├── beeline
│ ├── docker-image-tool.sh
│ ├── find-spark-home
│ ├── load-spark-env.sh
│ ├── pyspark
│ ├── run-example
│ ├── spark-class
│ ├── sparkR
│ ├── spark-shell
│ ├── spark-sql
│ ├── spark-submit
├── conf
│ ├── fairscheduler.xml.template
│ ├── log4j.properties.template
│ ├── metrics.properties.template
│ ├── spark-defaults.conf.template
│ ├── spark-env.sh.template
│ └── workers.templateUn Job peut être soumis de plusieurs manières, de façon interactive avec le Spark-shell, Pyspark pour le python, via une class avec le spark-class ou encore un jar avec le spark submit.
Note: le script spark-env.sh situé dans le répertoire conf permet de renseigner les adresses IP et ports des noeuds follower en mode Spark cluster.
Scala
Voici la structure d’un projet sbt:
├── build.sbt
├── project
│ └── target
├── src
│ ├── main
│ │ └── scala
│ │ └── MeanLength.scala
│ └── test
│ └── scala
└── targetname := "spark-demo"
version := "0.1"
scalaVersion := "2.12.14"
val sparkVersion = "2.4.4"
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % sparkVersion % "provided"
, "org.apache.spark" %% "spark-sql" % sparkVersion
)
idePackagePrefix := Some("com.bmeynier.article")Note: sbt est l’outils de build et de gestion des dépendances du Scala. Il est également possible d’utiliser Maven
RDD
import org.apache.spark._
import org.apache.spark.SparkContext._
import org.apache.spark.rdd.RDD
object MeanLength {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("mean-length")
val sc = new SparkContext(conf)
val entry = sc.textFile("/home/baptiste/Workspace/ventreDeParis.txt")
val words = entry.flatMap(l => l.split(" "))
val rdd_count_words = words.map(m => ("WORDS", 1)).reduceByKey{case (x,y) => x + y}
val rdd_count_letters = words.map(m => ("LETTERS", m.length())).reduceByKey( _ + _ )
val letters_count = rdd_count_letters.collect()(0)._2
val words_count = rdd_count_words.collect()(0)._2
val means = letters_count / words_count.toFloat
println("The words mean is:"+means)
}
}Générer un jar:
sbt clean packageSoumettre le script à Spark via un Jar:
spark-submit target/scala-2.12/spark-demo_2.12-0.1.jarDataframe
Le dataframe est une API haut niveau du module Spark SQL, il s’agit en quelque sorte d’un RDD survitaminé! L’idée est de pouvoir traiter un flux à la manière d’une requête SQL.
import org.apache.spark._
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.{split,explode,lit,length,sum}
object Code {
def main(args: Array[String]) {
val spark = SparkSession.builder().getOrCreate()
import spark.implicits._
val data = spark.read.format("text").load("/home/baptiste/Workspace/ventreDeParis.txt")
val wordsTab = data.select(split(data("value")," ").alias("column1"))
val words = wordsTab.select(explode(wordsTab("column1")).alias("word"))
val res = words.groupBy("word").count
val table_with_length = words.withColumn("length",length(words("word")))
table_with_length.show()
val moy = table_with_length.select(mean(table_with_length("length")).alias("mean"))
moy.show(false)
res.show
}
}Note: Il est tout à fait possible d’écrire son applicatif en python via PySpark, il faudra toutefois s’attendre à des performances légèrements moins bonnes que dans un langage interprété nativement par la JVM.
La console d’administration
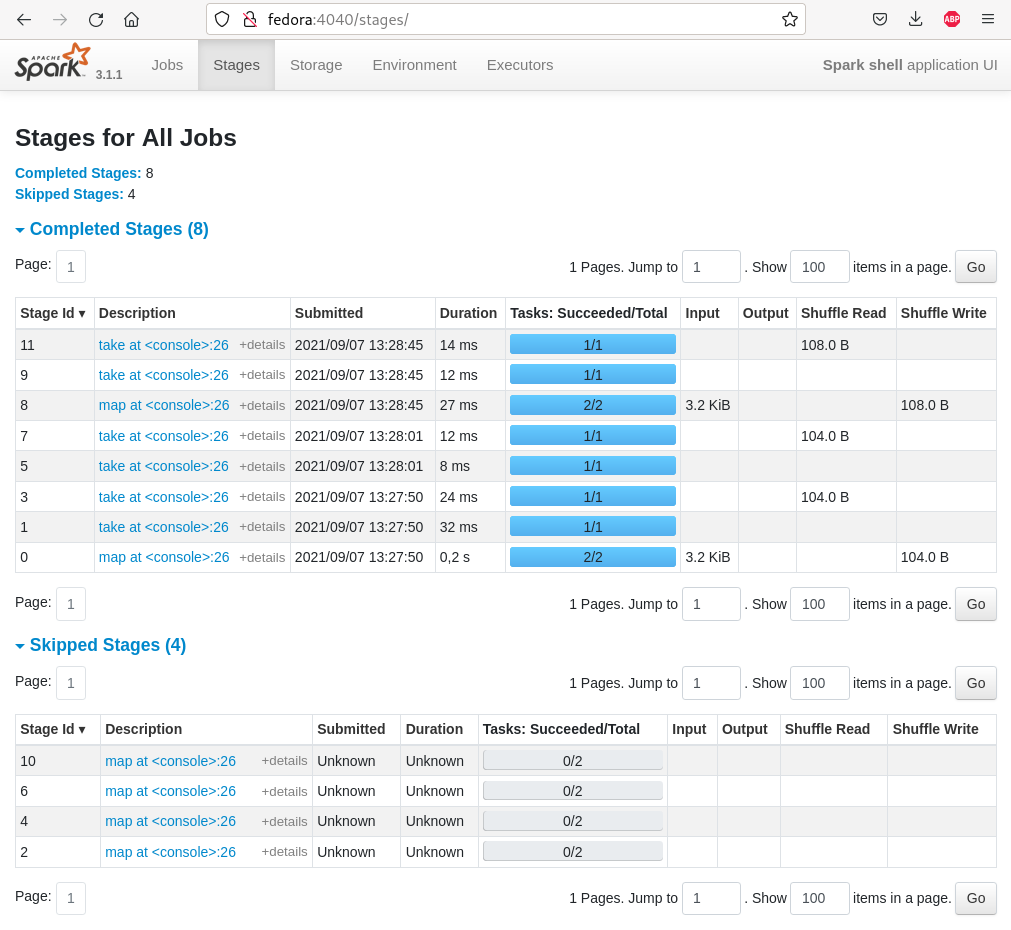
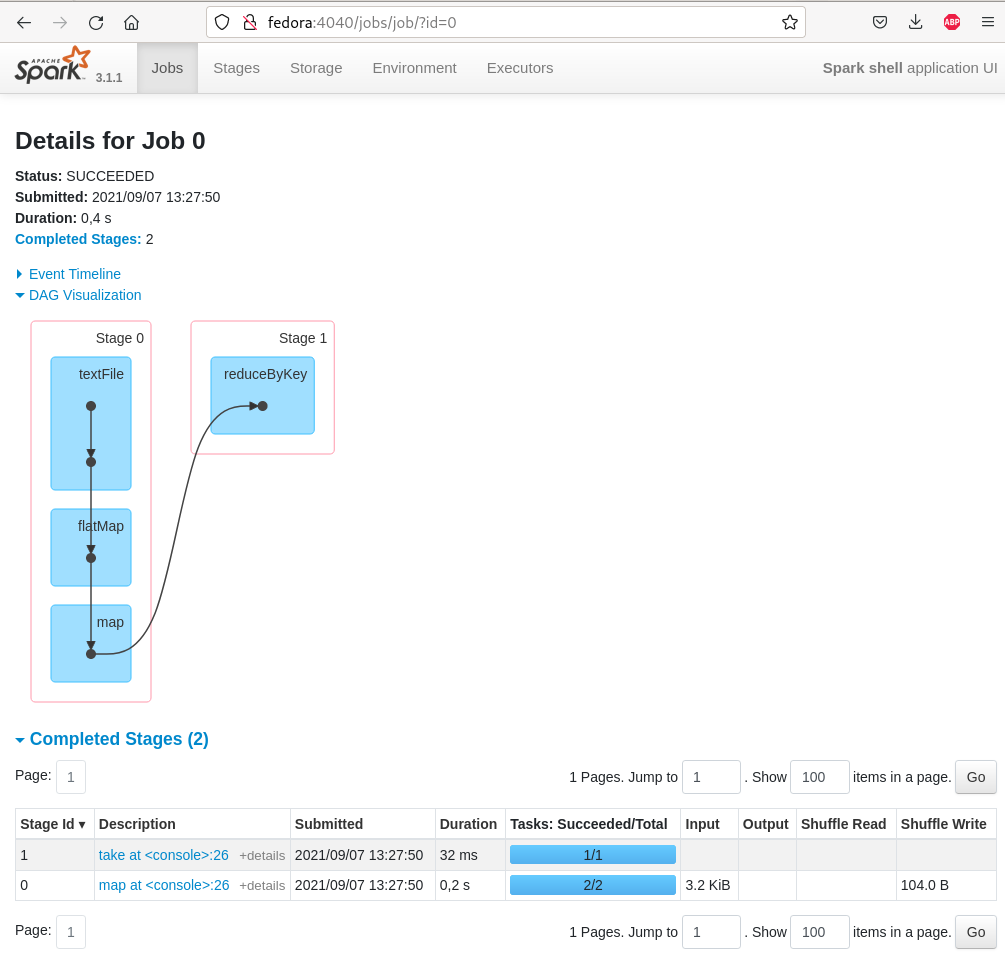
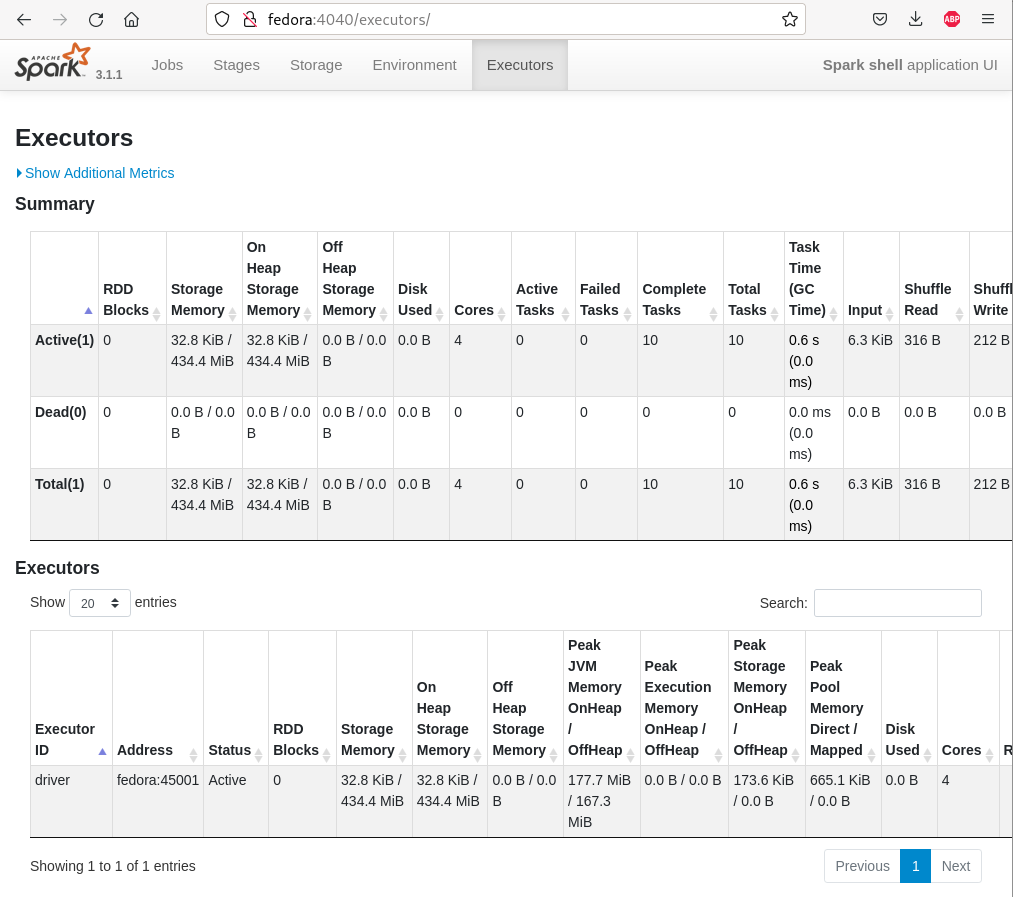
Code source

Code source
Comptes Twitter à suivre
https://twitter.com/databricks
https://twitter.com/matei_zaharia?ref_src=twsrc%5Egoogle%7Ctwcamp%5Eserp%7Ctwgr%5Eauthor
https://twitter.com/jeffdean?lang=fr
https://twitter.com/michaelarmbrust?lang=fr
Références
https://github.com/databricks/Spark-The-Definitive-Guide
https://livebook.manning.com/book/mastering-large-datasets/chapter-5/9
https://dzone.com/articles/what-is-data-validation
http://b3d.bdpedia.fr/spark-batch.html
https://spark.apache.org/docs/latest/hardware-provisioning.html
https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html
https://spark.apache.org/docs/latest/api/scala/org/apache/spark/index.html
https://techvidvan.com/tutorials/spark-architecture/
https://sparkbyexamples.com/spark/spark-shuffle-partitions/
https://medium.com/expedia-group-tech/start-your-journey-with-apache-spark-part-1-3575b20ee088
https://meritis.fr/spark-shuffle/
https://univalence.io/blog/articles/shuffle-dans-spark-reducebykey-vs-groupbykey/
https://blog.engineering.publicissapient.fr/2017/09/19/tester-du-code-spark-2-la-pratique/
https://itnext.io/spark-cassandra-all-you-need-to-know-tips-and-optimizations-d3810cc0bd4e
https://opencredo.com/blogs/deploy-spark-apache-cassandra/
https://www.inpact-hardware.com/article/1751/lextraordinaire-evolution-stockage
https://www.securedatarecovery.com/blog/hdd-storage-evolution
https://www.ibm.com/ibm/history/exhibits/storage/storage_3330.html
https://blog.acelaboratory.com/reading_speed.html
https://cedric.cnam.fr/vertigo/Cours/RCP216/tpGraphes.html
https://spark.apache.org/docs/latest/running-on-kubernetes.html
Un article d’une rare qualité! Cela m’a appris beaucoup